
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- pipline hazards
- cache coherence
- theta join
- pipelined cache
- directory based coherence protocol
- cache optimization
- dynamic scheduling
- Cache
- structural hazard
- transactional memory
- cache coherence miss
- load linked
- register renaming
- store conditional
- Subquery
- pipelined
- atomic exchange
- speculative execution
- branch prediction
- nonblocking cache
- moesi
- ISA
- dependence
- 관계형 모델
- sequential consistency
- sql
- multibanekd cache
- mesi
- way prediction
- relational model
- Today
- Total
공대생의 공부흔적
[컴퓨터구조#6] 캐시(고급) - 대체 정책, 삽입 정책, 멀티코어에서의 캐시 위계 본문
이번 글에서는 캐시와 관련된 고급 주제들에 대해 다룰 것이다.
목차
1. 대체 정책: LRU, PLRU, NRU, Adaptive policy
2. 삽입 정책: LRU, OPT, LIP, BIP
3. 멀티코어에서의 캐시 위계
1. 캐시 대체 정책 Cache Replacement Policy
캐시 내 데이터가 다 찬 경우, 새로운 데이터를 넣기 위해서는 이미 있던 데이터 중 하나를 빼야 한다. 어떤 데이터를 뺄지 고르는 데 여러 방법이 존재할 수 있다. 이때 사용하는 정책을 캐시 대체 정책이라고 한다.
간단히 생각해보면, 가장 긴 재사용 distance를 가지고 있는 블록, 즉 해당 블록에 대한 다음 접근이 가장 먼 미래에 있는 블록을 evict하면 된다. 하지만 이는 미래에 대한 지식을 필요로 한다. 따라서 실제 시스템에서 이를 구현할 수 없지만, trace 시뮬레이션을 통해 모델링할 수는 있다.
- 4-way associative 캐시에서 {X,A,B,C,D,X}의 접근 시퀀스를 생각해 보자. LRU 정책에 따르면, X를 빼고 D를 넣어야 한다. 하지만 D 시점에서 미래 접근을 알고 있다면 X가 오기 때문에 B를 evict해야 한다(optimal).
LRU (Least Recently Used)
가장 많이 쓰이는 방법으로, 과거를 통해 미래를 예측하는 방법이다. (temporal locality 활용)
associative 캐시에 적용하는 경우 many ways로 scale이 필요하다.
- 2-way 캐시: set당 1개의 비트만 필요하다.
- 2 이상의 associativity에 대해서는 어렵고 비싸다.
- way 내 데이터들 간 순서를 인코딩하기 위한 리스트 오버헤드는 블록당 log_2(assoc) bit가 필요하다.
- 2-way: log_2(2) = 1bit / block → 두 데이터의 순서를 0/1로 구분할 수 있다. 총 2비트가 필요하다.
- 4-way: log_2(4) = 2bit / block → set당 4개의 블록이 존재하며, 블록당 순서를 나타내기 위한 2개의 비트(00~11)가 필요하다. 총 2*4=8비트가 필요하다.
- 8-way: log_2(8) = 3bit / block → 총 3*8=24비트의 오버헤드
way가 커질수록 비트 오버헤드도 매우 커지기 때문에 LRU를 실제 상황에 그대로 적용하기에는 약간 무리가 있다.
Practical Pseudo-LRU
실제 LRU 대신 이진 트리를 활용해 pseudo-LRU를 구현할 수 있다. 각 데이터의 정확한 age 대신 트리 내 인코딩된 부분적인 순서만 유지하여 대략적인 측정값을 사용한다. 각 노드는 가리키는 두 노드 중 어떤 것이 older/newer인지를 나타내며, 각 접근마다 해당 블록에 가기까지 걸린 path의 노드들을 업데이트한다(flip). (P)LRU victim을 찾으려면 older pointer를 따라가면 된다.
예를 들어, A,B,C,D,E 순서로 접근되었다고 하자. 각 노드에서 1은 오른쪽이 더 older라는 것을, 0은 왼쪽이 더 older라는 것을 나타낸다. 아래 그림과 같이 Pseudo LRU 트리를 만들 수 있다.
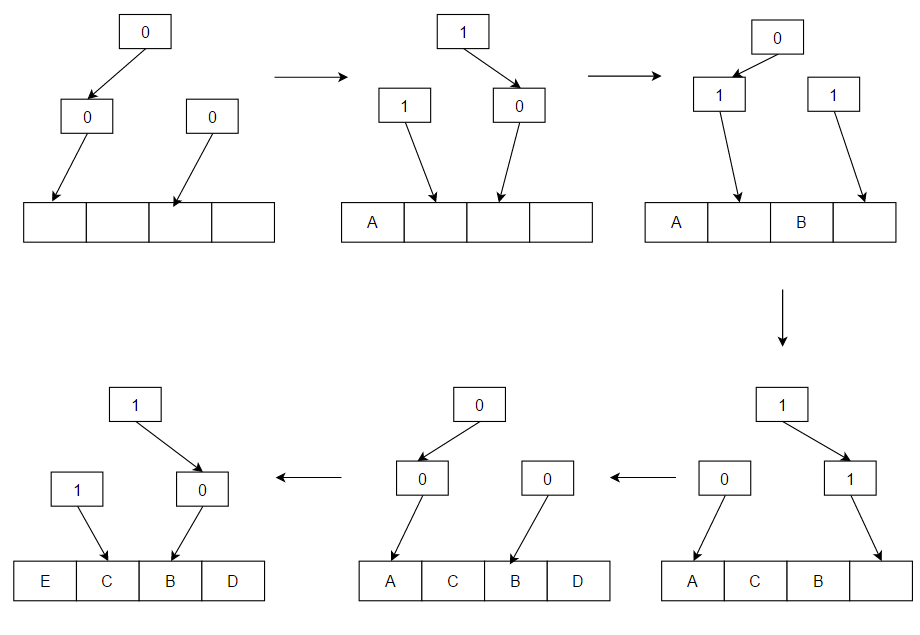
LRU와 달리, PLRU는 블록당 (a-1)/a bit의 오버헤드만 가진다. 위 예시에서는 4-way associative 캐시이고, (3/4)*4 = 총 3개의 오버헤드 비트를 가진다. 이는 트리 상에서도 확인할 수 있다.
실제 LRU의 단점
다음과 같은 시나리오에서는 LRU가 좋은 선택이 아니다.
- 스트리밍 데이터/스캔: X0, X1, ... , Xn : 실질적으로 temporal use가 없는 경우
- Thrashing: 재사용 distance가 associativity보다 큰 경우. → temporal 재사용이 존재하지만 LRU 실패
- e.g. 4-way인데 A,B,C,D,E 접근이 반복되는 경우
- 모든 블록이 MRU에서 LRU 순서대로 접근되는 경우
- associativity보다 큰 n개의 데이터를 접근하는 경우 → 스캔/thrash 이후에 남는 블록이 없다.
- 스캔 이후 많은 conflict 미스를 일으키게 된다.
Not Recently Used (NRU)
LRU를 근사하는 방법으로, 블록당 1비트로 NRU state를 유지한다.
블록이 처음 install되면 (재사용을 가정하고) NRU 비트를 0으로 설정하며, 접근되면 (재사용이 관찰되었으므로) NRU 비트를 0으로 설정한다. eviction은 NRU 비트가 1인 블록에 대해 일어난다. 만약 모든 블록이 0인 경우, eviction은 모든 블록을 NRU = 1이 되도록 강제하고, 하나를 victim으로 고른다(pseudo-random, rotating, left-to-right 등 다양한 방법).
비슷한 방법으로 가상메모리의 clock 알고리즘이 있다.
strict한 LRU 순서보다는 randomizing eviction에 의존하여, 어느 정도의 스캔 / thrash 저항성을 제공한다.
인텔 Itanium, Sparc T2에 의해 사용된다.
새로운 블록 삽입
여러 방법이 존재한다.
- (일반적인 베이스라인) MRU : 새로운 블록이 재사용될 가능성이 높을 것이라 가정
- LRU : 새로운 블록이 재사용되지 않을 것이라 가정. 새로운 블록에 대한 다음 hit은 해당 블록을 MRU 위치로 이동시킴
- (half MRU) assoc/2 위치
- 적응형 정책(Adaptive insertion policies for high-performance caching, Quersh et al., ISCA 2007): streaming 데이터나 캐시보다 큰 응용의 working set의 경우 절대로 다시 사용되지 않는 캐시라인이 생기게 된다. 따라서 만약 working set이 캐시 크기보다 크다면, 차라리 working set을 어느 정도 유지하는 것이 낫다.
2. 캐시 삽입 정책 Cache Insertion Policy
캐시 대체 정책에는 두 가지 구성 요소가 있다.
- Victim Selection: 새로운 캐시라인을 위해 어떤 라인을 대체할 것인지? (e.g. LRU, 랜덤, FIFO, LFU)
- Insertion Policy: 새로 들어오는 캐시라인을 가능한 replacement list 중 어느 곳에 넣을지? (e.g. MRU)
지금까지는 victim selection 위주로 보았고, 이제부터는 삽입 정책에 대해 알아보자. 둘은 얼핏 비슷해 보이지만, 삽입 정책에 약간만 변화를 줘도 memory-intensive 워크로드에 대해서는 캐시 성능을 크게 향상시킬 수 있다.
LRU-Insertion Policy (LIP)
다음과 같이 a~h의 접근 패턴이 있는 상황에서, 새로운 i 블록이 접근된다고 해 보자.
기존 LRU policy에 따르면, (1)과 같이 LRU 블록(h)을 evict하고 새로운 MRU 자리에 i 를 추가하게 된다.
하지만 LIP policy에 따르면, (2)와 같이 LRU 블록(h)을 evict하고 그 LRU 자리에 새로운 데이터를 추가한다.
| MRU | LRU | |||||||
| a | b | c | d | e | f | g | h | |
| (1) LRU | i | a | b | c | d | e | f | g |
| (2) LIP | a | b | c | d | e | f | g | i |
Biomodal-Insertion Policy (BIP)
LIP의 경우 이전의 older 캐시라인들은 더 이상 업데이트되지 않는다는 문제가 있다. 즉 MRU position에는 캐시라인을 자주 업데이트하지 않는 것이다. e를 biomdal throttle 파라미터로 하여, 다음과 같이 경우에 따라 MRU와 LRU를 나누어 진행할 수 있다.
if (rand() < e)
Insert at MRU position;
else
Insert at LRU position;작은 e 값에 대하여 BIP는 LIP의 thrashing protection을 유지하면서도 working set의 변화에 대응할 수 있다.
a1~aT가 N번 순차 접근되고, 그 이후 b1~bT가 N번 순차 접근되는 상황이 있다고 가정해보자. (접근 스트림은 T개의 블록을 가지며 N번 반복된다.) 캐시는 K개의 블록을 갖고 있다. K<T이고 N>>T이다. 이때 정책별 hit rate은 다음과 같다.
| (a1 a2 ... aT)^N | (b1 b2 ... bT)^N | |
| LRU | 0 | 0 |
| OPT | (K-1)/(T-1) | (K-1)/(T-1) |
| LIP | (K-1)/T | 0 |
| BIP (small e) | ≈ (K-1)/T | ≈ (K-1)/T |
조금 더 쉽게 생각하기 위해, (a b c d e)가 N번 반복되고 4-way associative 캐시가 있다고 해보자.
- 캐시 용량 K보다 스트림 데이터 수 T가 더 크기 때문에 LRU 정책에서는 hit이 0이다.
- abcd까지 접근되었을 때 e가 들어오기 위해 a가 evict되고, bcde 상태에서 다음에 다시 a가 들어오기 위해 b가 evict되고, cdea에서 b가 들어오기 위해 c가 evict되고 ... 반복
- 미래를 알고 있는 최적의 시나리오에서는,
- abcd까지 접근되었을 때(1 miss) 미래 접근 스트림(eabcde...)에서 가장 멀리 있는 d가 evict된다. 캐시에 abce가 있는 상태로 a,b,c까지 hit되고(K-1=3 hit), 이후 d가 접근될 때 마찬가지로 미래 접근 스트림(deabcd...)에서 가장 멀리 있는 c가 eivict되어 캐시에 abde가 있는 상태로 e,a,b까지 hit되고, 그 다음 같은 방법으로 b를 evict하며 반복된다. 즉, 4번(T-1)의 주기마다 3번(K-1)의 hit이 달성되어 (K-1)/(T-1)의 hit rate이 도출된다.
- LRU 자리에 새로운 아이템을 넣는 LIP에는 OPT와 비슷하지만 조금 낮은 hit rate을 보여준다. 이는 항상 낭비되는 첫 번째 아이템이 있기 때문이다.
- abcd까지 접근되었을 때(1 miss) a가 evict되고, 그 자리에 e가 삽입되어 캐시에 ebcd가 있는 채로 다시 a 접근(1 miss)이 들어온다. 다시 LRU자리인 e가 evict되어 캐시에 abcd가 있는 채로 b,c,d 접근이 hit(K-1=3)이 된다. 이후 e에 대해 a가 evict되고 ebcd인 채로 다시 abcd .. 반복된다. 5번(T)의 주기마다 3번(K-1)의 hit이 달성된다.
- 이후 (f g h i j)가 N번 반복되는 경우를 생각해보자. LIP정책에서는 LRU 자리의 캐시 아이템만 바뀌기 때문에 abcd 캐시에서 fbcd, gbcd, hbcd, ibcd, jbcd와 같이 두 번째 접근에 대해서는 한 개의 데이터만 캐시에 저장되므로 hit rate은 0이 된다.
- 작은 e 값을 갖는 BIP의 경우, 대부분의 경우 LIP로 예외적인 경우 LRU로 저장된다. 따라서 LIP에 근사한 hit rate을 보여준다. pure LRU보다 훨씬 좋은 hit rate을 보여주는 것을 알 수 있다.
Dynamic Insertion Policy (DIP)
LIP와 BIP를 사용하는 경우, L2 캐시 미스가 줄어드는 경우가 대부분이지만 LRU-friendly 워크로드에 대해서는 캐시미스를 크게 늘리기도 한다.
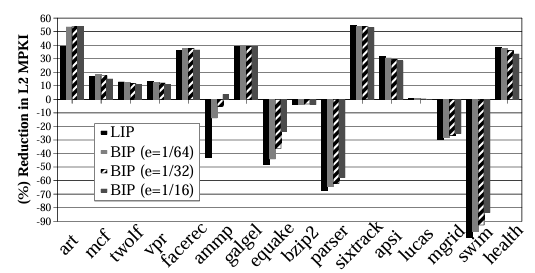
따라서 LRU-friendly 워크로드와 BIP-friendly 워크로드를 모두 만족할 수 있는 DIP가 존재한다. DIP는 LRU/BIP 두 정책을 모니터링하고, 잘 작동하는 정책을 골라 캐시에 적용함으로써 구현된다. set-dueling을 통해 이를 구현할 수 있다.
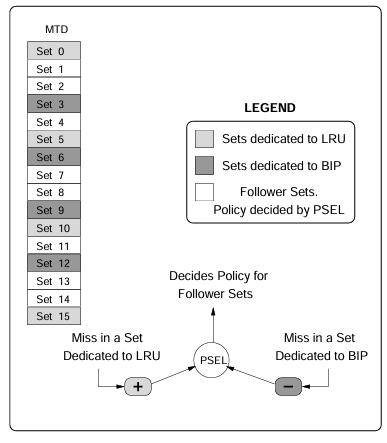
DIP via Set Dueling
Set dueling에서는 캐시를 다음 세 부분으로 나눈다: 지정된 LRU set, 지정된 BIP set, Follower set (winner of LRU, BIP). 단일 미슨느 이 셋 중 하나의 셋으로 들어가게 된다.
n-bit saturating 카운터는 LRU set에 대한 미스에는 counter++(increment), BIP set에 대한 미스에는 counter--(decrement)를 수행한다. 만약 PSEL의 MSB가 0이면 LRU로, 1이면 BIP로 정책을 결정하게 되는 것이다.
3. 멀티코어에서의 캐시 위계
on-chip 통합의 경우 다음과 같은 장점이 있다.
- on-chip component를 높은 대역폭으로 연결 가능 (IO pin 제한 없음, on-chip 인터커넥트가 off-chip 인터커넥트보다 쌈)
- 낮은 인터커넥션 지연 시간 (on-chip이 off-chip보다 훨씬 빠르다)
- 칩 경계 없음 (구성 요소의 유연한 모양과 위치 가능)
- 프로세서의 tight coupling이 가능하며, 이들 간 자원을 공유하게 된다.
즉, 높은 대역폭과 낮은 지연 시간의 interconnection은 캐시 설계에 유연성을 더해준다. 근본적인 캐시 trade-off는 크고 더 많은 포트를 가질수록(더 많은 접근 대역폭) 더 느리다는 것이다. 멀티코어에서 private 과 shared 캐시의 경우 hit latency와 miss rate간의 trade-off, 그리고 자원 할당과 간섭 효과 간 trade-off를 겪는다.
| Private Cache | Shared Cache |
| - 단일 혹은 전통적인 멀티코어 프로세서에서 사용되어 왔다. shared 캐시에 비해 빠른 hit time을 가지며, 용량이 작다. - 하나의 프로세서를 serve해야 하므로 낮은 대역폭 요구량을 가진다. hit time이 빠르므로 miss resolution time이 빨라 미스 요청을 일찍 보낼 수 있다. - L2 coherence 메카니즘은 프로세서 간 통신을 처리하며, 다른 프로세서와의 간섭 문제가 없다.(no negative interference) |
- private 캐시보다 크기 때문에 느린 hit time을 가지며, 높은 대역폭 요구량을 가지고 miss resolution time이 느리다. - 높은 associativity를 필요로 한다. - 프로세서 간 캐시 용량을 공유한다. 따라서 working set이 쓰레드 간 균일하지 않을 때 캐싱 효율성이 높고, 전체 미스를 줄일 수 있다. - 다른 프로세서에 의해 positive 간섭을 받는다. (공유 데이터에 대한 프리페칭 효과, 하나의 프로세서가 메모리에서 공유 데이터를 가져오면 다른 프로세서는 미스 없이 그 데이터를 사용할 수 있다) |
| private small L2 caches - 상대적으로 느린 지연시간: 10~20 cycle - 크기: 256KB ~ 1MB - 각 코어에 대해 간섭받지 않는 private 캐시를 제공 |
large shared L3 cache - LLC (last level cache) - 느림: 30~40 cycle - 크기: > 4MB (더 커지고 있음 - 여러 코어 간 공유됨 |
* 동일한 응용에 대해서는 shared가 낫고, 같은 응용의 여러 복사본에 대해서는 private이 낫다.
대규모 공유 캐시 구현
높은 대역폭과 high associativity를 필요로 하므로 단순한 캐시 디자인은 너무 느리다.
- Multi-bank(multi-slice) 접근: 각 뱅크는 독립적으로 접근 가능하며, 뱅크별로 독립적인 컨트롤러가 존재한다.
- 주소 기반의 뱅크 할당: N개의 뱅크가 있다면, 최선의 경우 N개의 simultaneous 접근, 최악의 경우 1개의 접근을 serve할 수 있다. 뱅크 할당은 물리 주소에 의해 정적으로 할당된다. (학계에서는 동적 맵핑도 연구되었음: D-NUCA)
- way-based 뱅크 할당: 각 뱅크는 assoc/N ways를 커버하며, associativity를 효과적으로 늘릴 수 있다.
실제 예시로는 IBM Power 4/5는 2개의 프로세서(주소 기반)에 의해 공유되는 3개의 뱅크를, Sun-T1은 8개의 프로세서(주소 기반)에 의해 공유되는 8개의 뱅크를, 인텔과 AMD 프로세서는 공유 L3(way 기반) 캐시를 적용했다.
캐시 공유에서는 코어 간 다음과 같은 충돌이 발생할 수 있다.
- High-miss 쓰레드와 low-miss 쓰레드가 캐시를 공유
- High-miss 쓰레드가 low-miss 쓰레드에 필요한 데이터를 evict
- High-miss 쓰레드가 캐시를 효과적으로 사용하지 않음
- Low-miss 쓰레드가 high-miss 쓰레드에 의해 부정적 영향을 받음
- 최악의 경우, 한 쓰레드는 다른 쓰레드의 실행을 거의 막을 수도 있다.
이런 경우를 막기 위해, 아키텍처적으로는 정적/동적 파티셔닝을, os에서는 페이지 컬러링이나 스케줄링을 적용할 수 있다.
e.g. Intel CAT(Cache Allocation Technology): 캐시 파티셔닝, CLOS(Class of Service), NVIDIA MIG(Multi-Instance GPU)


