
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- way prediction
- pipline hazards
- sql
- structural hazard
- pipelined
- Cache
- multibanekd cache
- branch prediction
- 관계형 모델
- register renaming
- Subquery
- load linked
- mesi
- nonblocking cache
- cache coherence
- cache coherence miss
- cache optimization
- relational model
- moesi
- ISA
- store conditional
- atomic exchange
- transactional memory
- pipelined cache
- theta join
- sequential consistency
- dependence
- dynamic scheduling
- directory based coherence protocol
- speculative execution
- Today
- Total
공대생의 공부흔적
[컴퓨터구조#5] 프리페치 (Prefetching) 본문
이번 글에서는 프리페칭에 대해 알아볼 것이다.
목차
1. 프리페칭
2. What, When, Where, How
3. 하드웨어 프리페처: Next-line, Stride, Locality-based
4. 프리페처 성능
5. Markov Prefetching
1. 프리페칭 (Prefetching)
프로그램이 데이터를 필요로 하기 전에 미리 fetch해오는 것. → miss rate과 miss latency를 모두 줄일 수 있다.
왜 필요한가?
- 메모리 지연 시간은 매우 길기 때문에, 정확하고 빠르게 프리페치할 수 있다면 이러한 긴 지연 시간을 줄이거나 없앨 수 있다.
- Compulsory cache miss를 없앨 수 있다.
- capacity, conflict, coherence로 인한 캐시 미스는 여전히 발생한다.
프리페칭은 미래에 어떤 주소가 접근될지 예측하는 것도 포함한다. (프로그램이 예측 가능한 미스 주소 패턴을 갖는 경우 유효하다.) 하지만, 이 예측이 틀렸다고 해서 정확도correctness에 영향을 주지는 않는다. 잘못 예측되어 프리페치된 주소는 단순히 사용되지 않고 끝나기 때문이다. 즉 따로 recovery를 해 줄 필요가 없다.(하지만 어쨌든 쓸데없는 값이 캐시에 남아 있는 것이기 때문에 캐시 오염 문제와 메모리 대역폭 낭비 문제는 존재한다.) 이는 브랜치 misprediction 시 flush 및 recovery가 필요한 것과 대조된다.
보통 현대 시스템에서 프리페칭은 캐시 블록 단위로 수행되며, 하드웨어/컴파일러/프로그래머에 의해 수행될 수 있다. 예를 들면 L2 미스 시 하드웨어 스트림 프리페처를 통해 L2 캐시에 프리페칭할 수 있다.
2. What, When, Where, How
그렇다면 프리페치는 무엇을(어떤 주소를), 언제(프리페치 요청을 언제 initiate할지), 어디서(프리페치된 데이터를 어디에 둘지), 어떻게(소프트웨어, 하드웨어, 실행기반, 협력적) 해야 할까? 각 질문별로 고려사항을 알아보자.
What: 어떤 주소를 프리페치하는가?
필요 없는 데이터를 프리페칭하는 경우 다음과 같은 수많은 자원을 낭비하게 된다. 따라서 정확한 주소를 가져오는 것이 중요하다.
- 메모리 대역폭
- 캐시(혹은 프리페치 버퍼) 공간
- 에너지 소모
*이전 글에서 살펴보았듯, 프리페치의 정확도 accuracy = used prefetches / sent prefetches이다.
과거 접근 패턴에 기반하여 프리페치할 주소를 예측할 수 있고, 혹은 데이터 구조에 대한 컴파일러 지식을 활용할 수도 있다. 프리페칭할 데이터를 고르는 데에는 프리페칭 알고리즘이 사용된다.
When: 언제 프리페치 요청을 시작하는가?
만약 너무 빨리 프리페칭한다면, 프리페치된 데이터는 실제로 사용되기 전에 스토리지에서 evict될 것이다.
반대로 너무 늦게 프리페칭된다면, 메모리 지연 시간을 줄이는 프리페칭 본래의 목적에 도달할 수 없다.
언제 데이터가 프리페치되느냐는 프리페처의 timeliness에 영향을 준다. 다음 두 방법으로 프리페처를 더 timely하게 만들 수 있다.
- (하드웨어 프리페처) 더 공격적aggressive으로 만들기: 프로세서의 접근 스트림보다 훨씬 앞서 있기
- 이때 aggressive는 가능한 많이 프리페치하여 coverage를 높인다(=accuracy는 자연스레 낮아짐)는 의미도 될 수 있다. (이 경우는 아님)
- (소프트웨어 프리페처) 코드 내에서 프리페치 명령어를 더 앞으로 이동
Where: 프리페치된 데이터를 어디에 저장하는가?/프리페처를 어디에 두는가?
| 캐시 | 프리페치 버퍼 | |
| 장점 | 간단한 디자인, 추가적인 버퍼 필요 없음 | 프리페치된 데이터로부터 필요한 데이터를 지킬 수 있음 → 캐시 오염 X |
| 단점 | 필요한 데이터를 evict시킬 수 있음 → 캐시 오염 |
더 복잡한 메모리 시스템 디자인 |
| 고려 사항 | 많은 현대 시스템은 프리페치 데이터를 캐시에 저장한다. - 인텔 펜티엄4, Core2, AMD system, IBM POWER 4,5,6, ... |
프리페치 버퍼를 어디에 둘지 프리페치 버퍼에 언제 접근할지 (병렬적 vs 캐시와 순차적으로) 프리페치 버퍼에서 캐시로 언제 데이터를 옮길지 프리페치 버퍼의 크기는 어떻게 할지 프리페치 버퍼를 coherent하게 유지해야 함 |
그렇다면, 어떤 레벨의 캐시에 데이터를 프리페치해야 하는지 정해야 할 것이다. (메모리에서 L2로, L1으로) 또한, L2에서 L1으로도 프리페치를 할 것인지도 생각해볼 수 있다.
또한, 프리페치된 데이터는 캐시 안의 어느 위치에 저장해야 할까? 프리페치된 블록을 일반적으로 저장된 demand-fetched 블록과 동일하게 봐야 할까? 프리페치된 블록은 필요한지 아닌지 여부가 알려져 있지 않다. 따라서 만약 LRU 정책을 사용한다면 demand block을 MRU position으로 바꿀 수 있다. 즉, 기존 replacement policy를 수정하여 demand-fetch 블록과 같이 사용되도록 만들어야 할까? 예를 들면 모든 프리페치 블록은 LRU position으로 바꿀 수 있다.
하드웨어 프리페처는 메모리 위계 상 어디에 있어야 하는가? 즉, 프리페처는 어떤 접근 패턴을 볼 것인가? 위치에 따라서 L1 hit와 miss, L1 miss만, L2 miss만 볼 수 있다. low level로 내려갈수록 캐시들에 의해 접근 패턴이 필터링된다.
더 complete한 접근 패턴을 보는 것은 프리페칭 시 더 좋은 accuracy와 coverage를 가능케 할 수 있지만, 프리페처가 더 많은 요청을 검사해야 한다는 것을 의미한다. 즉 bandwidth intensive하고 프리페처에 더 많은 port를 필요로 하게 된다.
How: 어떻게 프리페치할 것인가?
| 소프트웨어 프리페칭 | 하드웨어 프리페칭 | 실행 기반 프리페처 Execution-based prefetchers |
| - ISA가 프리페치 명령어를 제공 - 프로그래머나 컴파일러가 프리페치 명령어를 삽입해야 함 (effort) - 보통 regualr access pattern에 대해서만 잘 작동함 |
- 하드웨어가 프로세서 접근을 모니터링 - 패턴이나 stride를 기억하거나 찾음 - 자동으로 프리페치 주소를 생성 |
- 메인 프로그램에 데이터를 프리페치하는 쓰레드가 실행됨 - 소프트웨어/프로그래머나 하드웨어에 의해 모두 생성될 수 있다. |
소프트웨어 프리페칭
컴파일러/프로그래머가 코드의 적절한 위치에 프리페치 명령어를 위치시킨다. binding과 non-binding 두 종류가 있다.
- Binding: 일반적인 load를 사용하여 레지스터에 프리페치한다.
- 별도의 프리페치 명령어가 필요없지만, 레지스터를 사용하므로 Exception에 대한 우려나 데이터가 사용되기 전 다른 프로세서가 해당 값을 바꾸는 경우에 대해 생각해야 한다.
- Non-binding: 특별한 명령어를 통해 캐시에 프리페치한다.
- 캐시가 coherent하므로 별도의 coherent 이슈를 생각하지 않아도 되지만, 일반적인 load와 프리페치가 다르게 여겨지므로 복잡해진다.
다음과 같이 __prefetch 명령어를 통해서 구현이 가능하다.
/* 1 */
while (p) {
__prefetch(p->next);
work(p->data);
p = p->next;
}
/* 2 */
while (p) {
__prefetch(p->next->next->next);
work(p->data);
p = p->next;
}또한, 소프트웨어 프리페치는 매우 regular한 array 기반의 접근 패턴에 대해서만 잘 작동한다. 다음과 같은 고려사항들이 있다.
- 프리페치 명령어가 프로세싱/실행 대역폭을 차지함
- 얼마나 빨리 프리페치할지 정하는 것이 어렵다. Prefetch distance는 하드웨어 구현(메모리 지연시간, 캐시 크기, loop iteration 간 시간)에 따라 달라진다.
- 너무 멀리 가는 것은 정확도를 떨어트릴 수 있다.(중간에 브랜치가 존재할 수도 있음) 예를 들어 위 코드에서 2번처럼 너무 먼 미래까지 프리페치하는 것보다는 1번처럼 하는 것이 낫다.
- ISA에 특별한 프리페치 명령어가 필요한가? 꼭 그렇지는 않다. Alpha는 r31을 프리페치처럼 생각하고, PowerPC에도 dcbt (data cache block touch) 명령어가 있다.
- 일반적인 array 기반의 접근이 아닌 경우, 예를 들면 포인터 기반의 데이터 구조에서는 이를 이용하기 쉽지 않다.
마지막으로, 컴파일러가 프리페치를 언제 삽입해야 할지 생각해야 한다. 모든 로드 접근마다 프리페치하는 경우 메모리와 execution 대역폭 모두 intensive하다. 코드를 profile해서 미스가 날 것 같은 로드를 정해야 한다.(물론, 이 경우에도 profile input set이 representative하지 않은 경우를 생각해야 한다.) 또한, 미스가 일어나기 얼마 전에 프리페치할지 생각해야 한다. 보통은 매우 미리 프리페치해서 메인 메모리 지연시간의 100 cycle 정도 cover한다.
하드웨어 프리페칭
특화된 하드웨어가 로드/스토어 접근 패턴을 관찰해서 과거 접근 행동에 기반해 데이터를 프리페치한다.
시스템 구현에 잘 tuned될 수 있고, 여러 구현 간 성능 차이 측면에서 코드 이식성 문제code portability가 없으며, 명령어 실행 대역폭을 낭비하지 않는다. 하지만, 패턴을 탐지하기 위해 하드웨어 복잡성이 증가한다. 어떤 경우 소프트웨어가 더 효율적일 수도 있다.
이제 여러 가지 하드웨어 프리페처에 대해서 알아보자.
3. 하드웨어 프리페처
Next-Line Prefetchers
가장 간단한 형태의 하드웨어 프리페칭으로, demand access 혹은 demand miss의 다음 N개의 캐시라인을 항상 프리페칭하는 것이다. next sequential prefetcher라고도 부른다.
장점: 구현하기 간단하며 복잡한 패턴 탐지가 필요하지 않다. 순차적이거나 streaming 접근 패턴에 잘 작동한다.
단점: 불규칙한 패턴의 경우 대역폭을 낭비할 수 있다.(e.g. 접근 stride = 2인데 N=1인 경우, 프로그램이 높은 주소에서 낮은 주소로 메모리를 순회하는 경우)
Stride Prefetchers
Stride prefetcher에는 명령어 PC 기반, 캐시 블록 주소 기반의 두 가지 종류가 있다.
명령어 기반 stride prefetching
로드 명령어에 의해 가장 마지막에 접근된 메모리 주소와, 접근된 메모리 주소들 간의 거리를 기록하여, 동일한 로드 명령어가 다음 번에 fetch될 때, 마지막 주소 + stride 만큼을 프리페치한다.
즉, 각 로드 명령어 PC마다 다음과 같이 4개의 정보를 저장하는 하나의 entry를 저장하는 것이다. 하나의 entry만 찾아보면 된다는 장점이 있지만, 같은 PC에 대해서 항상 동일한 명령어만 프리페치하므로 불규칙한 패턴에 대비할 수 없다.
로드 명령어 PC로 인덱싱 ↓
| 로드 명령어 PC (tag) | 가장 마지막에 접근된 주소 | 마지막 stride | confidence (predictor가 얼마나 confident한지) |
| ... | ... | ... | ... |
| ... | ... | ... | ... |
또한, 로드가 다음번에 fetch되고 나서 프리페치를 initiate하는 것은 너무 늦을 수 있다. 로드는 fetch되고 거의 곧바로 데이터 캐시에 접근하기 때문이다.
해결책으로는 프리페처 테이블을 인덱싱하는 lookahead PC를 사용하거나, 여러 데이터를 프리페치하거나(last address+N*stride), 여러 개의 프리페치를 생성하는 방법이 있다.
캐시 블록 주소 기반 stride prefetching
블록 주소로 인덱싱 ↓
| 주소 tag | stride | control/confidence |
| ... | ... | ... |
| ... | ... | ... |
명령어 기반 stride prefetching과 다르게, 하나의 블록 주소에 대해 여러 entry를 비교해야 한다.
하지만, A, A+N, A+2N, A+3N, ...과 같은 패턴을 탐지할 수 있다. 즉 여러 명령어들 간의 상호작용으로 인해 생기는 stride를 알아낼 수 있다. 또한, 명령어 기반보다 프로세서 접근 스트림의 더 멀리까지 쉽게 도달할 수 있다. (lookahead PC도 필요 없다.) 다만, 서로 다른 여러 주소 범위를 찾아야 하므로 확인해야 할 데이터 주소가 더 많기 때문에 더 hardware intensive하다.
* Jouppi paper(ISCA 1990)에 소개된 stream buffer는 N=1인 경우의 캐시 블록 주소 기반 stride prefetching의 특별한 경우이다. (정확히 stride prefetching라고 볼 수는 없다) https://dl.acm.org/doi/10.1145/325164.325162
- 각 스트림 버퍼는 순차적으로 프리페치된 캐시라인의 스트림 하나씩을 저장한다.
- 로드 미스 발생 시, match되는 주소의 모든 스트림 버퍼의 head를 하나씩 확인한다.
- hit: 해당 entry를 FIFO에서 pop하여 캐시를 그 데이터로 업데이트한다.
- miss: 새로운 스트림 버퍼를 새로운 미스 주소에 할당한다. 이후 LRU policy를 위해 스트림버퍼를 재활용해야 할 수도 있다.
- 스트림 버퍼 FIFO는, 빈 공간이 있고 버스가 바쁘지 않을 때마다, 이어지는 캐시라인들로 연속적으로 채워진다.
- stride 예측 메커니즘과 합쳐져 non-unit-stride stream을 지원할 수 있다.
Locality Based Prefetchers
여러 응용에서 접근 패턴은 정확하게 strided되어 있지는 않는다. 어떤 패턴은 랜덤한 인접 주소처럼 보이기도 한다. 이런 접근들을 포착하기 위한 것이 지역성에 기반한 프리페칭이다.
- 대역폭에 intensive하며, stride detection이나 feedback mechanism을 통해 완화될 수 있다.
- 근처 주소를 프리페칭하는 것에 제한될 수 있다. (접근 주소가 large jump된다면 적절한 프리페치 주소를 찾을 수 없음)
- 하지만 실제 상황에서 매우 잘 작동한다. (single core systems)
(예시) Srinath et al., HPCA 2007 - Pentium 4 (Like) Prefetcher : 주소 범위를 트래킹하는 여러 개의 entry가 존재.
- invalid: 트래킹 entry가 트래킹하기 위한 스트림에 할당되지 않은 상태로, 모든 entry는 이 상태로 초기화된다.
- allocated: demand L2 미스(로드/스토어)는 해당 주소를 트래킹하는 entry가 없는 경우 새로운 트래킹 entry를 할당한다.
- training: 프리페처는 첫 미스에서 +- 16개의 캐시블록에서 발생하는 다음 두 번의 L2 미스에 기반하여 스트림의 방향(오름차순/내림차순)을 학습한다.
- monitor and request: 트래킹 entry는 메모리 영역을 시작 포인터(A)부터 끝 포인터(P)까지 검사한다. 두 지점 간 최대 거리는 프리페처가 요청을 보낼 수 있는 demand 접근 스트림이 얼마나 멀리 떨어져있는지를 나타내는 prefetch distance에 의해 결정된다. 만약 모니터링 메모리 영역 안의 캐시 블록에 대한 demand L2 캐시 미스가 발생한다면, 프리페처는 [P+1, ..., P+N] 캐시 블록을 프리페치로 요청한다. 이때 N은 prefetch degree라 한다. 프리페치 요청을 보낸 후 트래킹 entry는 A+N부터 P+N 주소 사이에 있는 메모리 영역을 검사한다.
4. 프리페처 성능
다음 세 가지 메트릭으로 프리페처 성능을 평가할 수 있다.
- Accuracy = used prefetches / sent prefetches
- Coverage = prefetched misses / all misses
- Timeliness = on-time prefetches / used prefetches
또한, 대역폭 소비(프리페처가 있을 때와 없을 때 사용된 메모리 대역폭. 가능하다면 idle bus 대역폭을 활용할 수 있다.)와 캐시 오염(캐시에 프리페치함으로써 생기는 추가적인 demand miss. 정량화하기 어렵지만 확실히 성능에 영향을 주는 요소이다.)도 고려 대상이다.
aggressive한 캐시와 conservative한 캐시 경우별로 어떻게 성능이 달라지는지 알아보자.
| Very Aggressive | Very Conservative |
| coverage ↑, accuracy ↓ | coverage ↓, accuracy ↑ |
| - 로드 접근 스트림에 잘 앞서 있다. - 메모리 접근 지연 시간을 더 잘 숨긴다. - 더 speculative하다. - coverage가 높고 timeliness가 더 좋다. - accuracy가 낮고 대역폭이 높으며 오염 문제가 있다. |
- 로드 접근 패턴에 더 가깝다. - 메모리 접근 지연 시간을 완벽히 숨기지 못할 수 있다. - 캐시 오염과 대역폭 경합을 줄일 수 있다. - accuracy가 높고 대역폭이 낮으며 오염이 덜하다. - coverage가 낮고 timeliness가 더 안 좋다. |
stride나 지역적인 접근 이외에도 Indirect array access, linked data structure, multiple regular strides(1,2,3,1,2,3,...), 혹은 랜덤 패턴 등 더 불규칙한 접근 패턴들이 존재한다. 모든 패턴에 잘 일반화되어 적용되는 프리페처는 존재하지 않는 것일까? Correlation based 프리페처, content-directed 프리페처, precomputation or execution-based 프리페처와 같은 프리페처들이 사용될 수 있다.
* correlation based 프리페처는 academic 접근으로 실제 프로세서에 통합되기는 어렵다.
5. Markov Prefetching
마지막으로, correlation 기반 프리페처의 일종인 Markov Prefetching에 대해 알아보자.
*Markov 모델: 현재 상태에만 기반해서 미래 확률을 예측하는 확률 모델.
예를 들어 캐시 블록 주소 접근 history가 다음과 같다고 해보자: A,B,C,D,C,E,A,C,F,F,E,A,A,B,C,D,E,A,B,C,D,C
이 히스토리를 바탕으로 다음과 같은 마르코브 모델을 만들 수 있다. A가 총 5번 접근되었는데, A 다음에 A가 한 번, B가 세 번, C가 한 번이므로 A->A와 A->C 확률이 0.2, A->B 확률이 0.3이 되는 것이다.
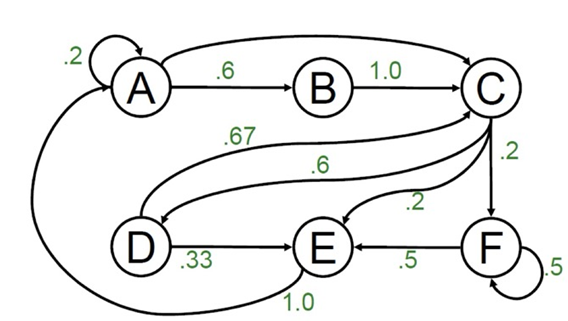
Markov 프리페처는 캐시 블록 주소를 기반으로 다음과 같은 정보들을 저장한다.
블록 주소로 인덱싱 ↓
| 캐시 블록 주소 tag | 프리페치 후보 1 | confidence | ... | 프리페치 후보 N | confidence |
| ... | ... | ... | ... | ... | |
| ... | ... | ... | ... | ... |
이때 confidence는 Markov 모델에 기초한 확률이 될 것이다.
특정 주소를 확인한 다음, 가능한(logically 접근할) 다음 주소를 트래킹한다.
프리페치 accuracy가 보통 낮기 때문에 최대 N개의 다음 주소를 프리페치함으로써 coverage를 높인다.
더 긴 히스토리를 사용하여 프리페치 정확도를 높일 수 있다. (현재 주소만 보는 대신 최근 K번의 로드 주소를 확인함으로써 어떤 주소를 다음에 프리페치할지 정한다. 몇 개의 로드 히스토리를 사용하는 것만으로도 정확도를 크게 높일 수 있다.)
- 장점: 임의의 접근 패턴(linked data structures, 스트리밍 패턴)도 커버할 수 있다.
- 단점
- 높은 coverage를 위해서는 correlation table이 매우 커야 한다. 모든 미스 주소와 그에 따른 미스 주소를 기록하는 것은 바람직하지 않다.
- 낮은 timeliness: 다음 접근/미스에 대한 프리페치가 이전 접근(/미스) 직후에 일어나기 때문에 lookahead가 제한적이다. → tight timeliness (cannot go far ahead)
- 많은 메모리 대역폭을 소비한다.
- compulsory miss를 줄일 수 없다. correlation은 미리 다 경험한 후에 프리페치하기 때문이다.
'Computer Architecture' 카테고리의 다른 글
| [컴퓨터구조#7-1] ILP (Instruction-Level Parallelism) - dependence, Out-of-Order execution, 동적 스케줄링 (0) | 2024.04.14 |
|---|---|
| [컴퓨터구조#6] 캐시(고급) - 대체 정책, 삽입 정책, 멀티코어에서의 캐시 위계 (0) | 2024.04.14 |
| [컴퓨터구조#4-2] 캐시 최적화 (Cache Optimization) - miss penalty, miss rate 줄이기 (0) | 2024.04.12 |
| [컴퓨터구조#4-1] 캐시 최적화 (Cache Optimization) - hit time 줄이기, 캐시 대역폭 늘리기 (1) | 2024.04.12 |
| [컴퓨터구조#3] 메모리 위계 (Memory Hierarchy) (0) | 2024.04.12 |


