
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- moesi
- pipline hazards
- dependence
- pipelined cache
- speculative execution
- load linked
- Subquery
- way prediction
- ISA
- directory based coherence protocol
- register renaming
- atomic exchange
- multibanekd cache
- cache optimization
- Cache
- 관계형 모델
- nonblocking cache
- sql
- theta join
- mesi
- cache coherence
- store conditional
- structural hazard
- branch prediction
- pipelined
- sequential consistency
- dynamic scheduling
- transactional memory
- cache coherence miss
- relational model
- Today
- Total
공대생의 공부흔적
[컴퓨터구조#4-1] 캐시 최적화 (Cache Optimization) - hit time 줄이기, 캐시 대역폭 늘리기 본문
[컴퓨터구조#4-1] 캐시 최적화 (Cache Optimization) - hit time 줄이기, 캐시 대역폭 늘리기
생대공 2024. 4. 12. 18:00참고: Computer Architecture: A Quantitative Approach (5th edition) - 2.1~2.3.
메모리 위계에 대해 살펴본 지난 글에 이어, 이번 글과 다음 글에서는 10가지 고급 캐시 최적화 기술에 대해서 살펴볼 것이다. 이번 글에서는 hit time을 줄이는 small and simple first level caches, way prediction, 그리고 캐시 대역폭을 늘리는 pipelined cache access, nonblocking, multibanked cache에 대해 알아볼 것이다.
2024.04.12 - [Computer Architecture] - [컴퓨터구조#3] 메모리 위계 (Memory Hierarchy)
[컴퓨터구조#3] 메모리 위계 (Memory Hierarchy)
참고: Computer Architecture: A Quantitative Approach (5th edition) - Appendix B. Reveiw of Memory Hierarchy 이번 글에서는 메모리 위계에 대해서 캐시 위주로 복습하고 넘어갈 것이다. 목차 1. 개요 지역성(temporal/spatial l
woohi.tistory.com
목차
- Small and simple first level caches
- Way prediction
- Pipelining cache
- Nonblock cache
- Multibanked cache
- Critial word first, Early restart
- Merging write buffer
- Code and compiler optimizations
- Hardware prefetching
- Compiler prefetching
이번 글에서 소개될 최적화 방법은 다음 5개의 메트릭을 기반으로 이루어진다.
- hit time 줄이기: 1번, 2번 → 전력 소모도 줄인다.
- 캐시 대역폭 늘리기: 3번, 4번, 5번 → 전력 소모에는 서로 다른 영향을 준다.
- miss penalty 줄이기: 6번, 7번 → 전력에는 거의 영향이 없다.
- miss rate 줄이기: 8번 → 컴파일 시간에 대한 개선은 확실히 전력 소모를 개선한다.
- 병렬성 활용해 miss penalty나 miss rate 줄이기: 9번, 10번 → 사용되지 않는 프리페치된 데이터 때문에 전력 소모를 늘린다.
1. Small and Simple First-Level Caches
다음 그래프에서 볼 수 있듯, 캐시 크기와 associativity가 증가할수록 접근 시간과 에너지 소모량이 증가한다.
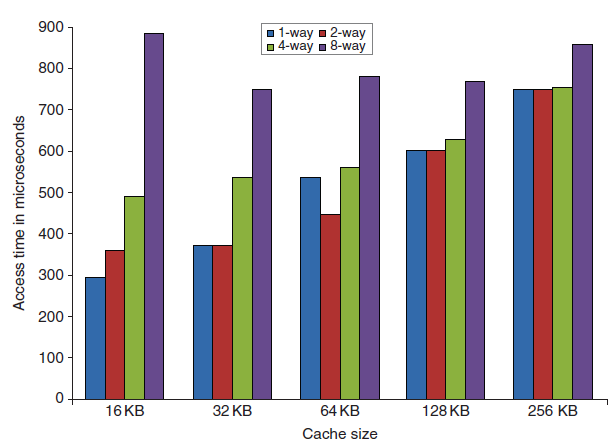
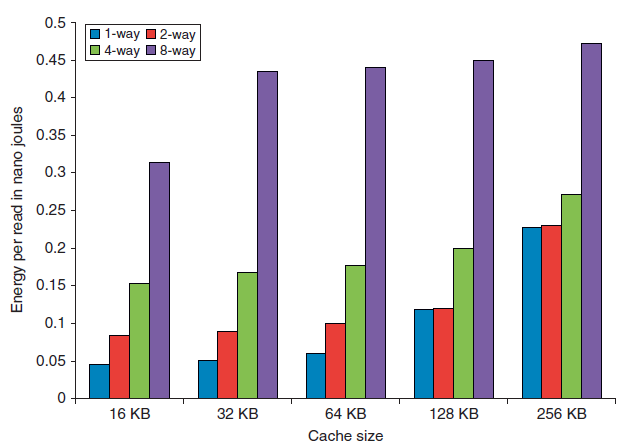
캐시 hit 발생 시 critical time path는 태그 메모리 addressing → 태그 비교 → 맞는 set 선택(set associative인 경우)의 세 단계로 이루어진다.
Direct-mapped 캐시의 경우 태그 비교와 데이터 이동 시간을 겹치게 할 수 있고, 낮은 associativity는 더 적은 캐시라인이 접근되므로 전력 소모를 줄여준다.
따라서 L1 캐시로는 작고 간단한 캐시를 사용하는 것이 첫 번째 최적화 방법이다.
2. Way Prediction
hit time을 개선하기 위해, 다음 번에 set 내 어떤 way가 접근될지 미리 예측함으로써 캐시 접근에 대한 에너지도 줄이는 방법이다. 예측한 way의 태그/데이터 어레이에만 접근하고, 만약 예측이 틀릴 경우 나머지 way를 탐색한다(hit time이 더 길어진다). 정확하게 예측한 경우 접근 속도도 빨라지고 전력 소모도 줄일 수 있다.
간단히 생각해 보면, 가장 최근에 접근된 waymost recently accessed way를 고르는 식으로 예측할 수 있다. 즉 temporal locality를 활용하는 것. 2-way의 경우 90%, 4-way의 경우 80% 이상의 예측 정확도를 보여주며 I-cache가 D-cache보다 더 높은 정확도를 보여준다고 한다.
90년대 중반에 MIPS R10000에서 처음 사용되었으며 ARM Cortex-A8에도 사용되었다.
*최근에는 associativity가 높기 때문에 way prediction 정확도가 높지 않아 많이 안 쓰는 것 같다고 한다.
3. Pieplining Cache
한 번에 하나의 접근만을 허용하는 것은 캐시 대역폭을 크게 제한한다. 따라서 캐시 접근을 파이프라인으로 만들어(e.g. 주소 decoding → 태그 접근 → 결과 mux) 대역폭을 향상시키는 최적화 방법이다.
예를 들어, instruction 캐시 접근을 파이프라인하여 인텔 펜티엄은 1 cycle, 프로~3은 2 cycles, 4~i7은 4 cycle의 접근 시간이 걸렸다. 이러한 변화는 파이프라인 스테이지 수를 증가시켜 브랜치 misprediction에 대한 penalty를 더 크게 만들 수 있다. (misprediction 발생 시 flush해야 할 명령어 수가 파이프라인에 의해 더 많아지기 때문) 또한, load를 발행(issue)하고 데이터를 사용하는 데 걸리는 clock cycle을 더 많이 만들 수 있다. 하지만, 높은 associativity를 활용하는 것을 더 쉽게 만들어 준다.
4. Nonblock Cache (lockup-free cache)
out-of-order execution을 허용하는 파이프라인 컴퓨터에서는, 프로세서가 data cache miss에서 stall할 필요가 없다. 예를 들어 해당 data cache가 missing data를 가져오기를 기다리면서 계속 다음 명령어를 fetch해올 수 있는 것이다. 이처럼 이전의 miss가 완료되기 전 hit을 허용하는 최적화 방법이다.: "hit under miss", "hit under multiple miss"
이 방법은 프로세서 요청을 무시하는 대신 그 동안 다른 일을 수행함으로써 effective miss penalty를 줄인다.
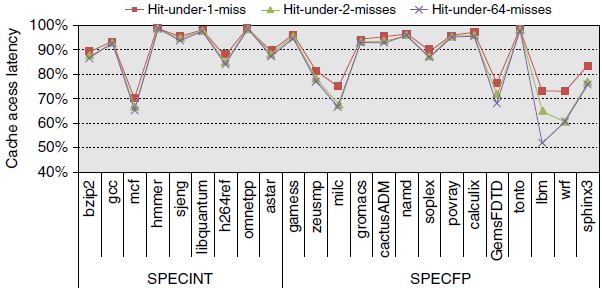
일반적으로 out-of-order 프로세서는 L2 hit인 L1 data cache miss의 miss penalty는 잘 숨길 수 있지만 L2나 더 낮은 레벨의 캐시 미스에 대해서는 그렇지 못하다. 이는 old memory instruction이 miss로 인해 pending일 때 다음 메모리 연산을 발행할 수 있으므로 ILP feature에 중요하다.
캐시 컨트롤러는 각 미스에 대해 여러 state machine을 유지한다 → Miss Status Holding Register (MSHR)
- MSHR은 미스 주소, 상태, 요청 PC 등을 저장하며, hit under miss 혹은 miss under miss를 지원한다.
- *miss under miss: 메모리 시스템이 여러 미스를 service할 수 있을 때만 beneficial하다.
메모리 접근을 병렬적으로 수행할 수 있기 때문에 최근엔 Memory-Level-Prallelism(MLP)라는 용어가 새로 나왔다.
얼마나 많은 outstanding miss를 숨길 수 있는지는 다양한 factor에 따라 달라진다.
- miss stream에서의 시간적/공간적 지역성
- responding memory/cache의 대역폭
- core/더 높은 캐시에서 최소한 그 정도의 접근(미스)를 initiate할 수 있는지
- 메모리 시스템의 latency
5. Multibanked Cache
캐시를 여러 개의 독립적인 뱅크로 조직하여 simultaneous 접근을 가능하게 하는 방법이다.
- ARM Cortex-A8: L2 캐시에 대한 1~4개의 bank
- Intel i7: L1에 4개의 bank, L2에 8개의 bank
접근들이 자연스럽게 펼쳐져 있을 때 bank는 가장 잘 작동한다. 즉 뱅크에 대한 주소 맵핑은 메모리 시스템의 일이다. 단순하게 주소를 블록에 순차적으로 펼치는 매핑 방식을 sequential interleaving이라 한다. 예를 들어 4개의 뱅크가 있다면 bank0은 addr % 4 = 0인 addr를, bank1은 addr % 4 = 1인 addr를 저장하게 되는 것이다.

여러 뱅크를 사용하는 것은 캐시와 DRAM의 전력 소모를 줄이는 방법이기도 하다.
'Computer Architecture' 카테고리의 다른 글
| [컴퓨터구조#5] 프리페치 (Prefetching) (0) | 2024.04.13 |
|---|---|
| [컴퓨터구조#4-2] 캐시 최적화 (Cache Optimization) - miss penalty, miss rate 줄이기 (0) | 2024.04.12 |
| [컴퓨터구조#3] 메모리 위계 (Memory Hierarchy) (0) | 2024.04.12 |
| [컴퓨터구조#2-2] 파이프라인(Pipelining) - Pipeline Hazards, Branch Prediction (0) | 2024.04.11 |
| [컴퓨터구조#2-1] 파이프라인(Pipelining) - 기초 (0) | 2024.04.11 |



