
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
- ISA
- relational model
- theta join
- pipline hazards
- multibanekd cache
- pipelined cache
- speculative execution
- nonblocking cache
- cache coherence
- load linked
- way prediction
- sql
- sequential consistency
- structural hazard
- dynamic scheduling
- Cache
- atomic exchange
- cache coherence miss
- store conditional
- cache optimization
- 관계형 모델
- pipelined
- register renaming
- transactional memory
- branch prediction
- directory based coherence protocol
- Subquery
- moesi
- mesi
- dependence
- Today
- Total
공대생의 공부흔적
[컴퓨터구조#3] 메모리 위계 (Memory Hierarchy) 본문
참고: Computer Architecture: A Quantitative Approach (5th edition) - Appendix B. Reveiw of Memory Hierarchy
이번 글에서는 메모리 위계에 대해서 캐시 위주로 복습하고 넘어갈 것이다.
목차
1. 개요
지역성(temporal/spatial locality)
2. 캐시
캐시 배치 정책: Direct-mapped/Associative Caches
캐시 대체 정책, 캐시 미스
캐시 메트릭: AMAT
6가지 기초 캐시 최적화 방법
다층 캐시(Multi-level caches)
1. 개요
기본적으로, 큰 메모리는 느리고 빠른 메모리는 작다. 이러한 특징과 병렬성을 바탕으로 빠르고 큰, 그리고 싼 메모리처럼 보이도록 구현하는 것이 메모리 위계의 목적이다.
가장 전형적인 방법은 지역성의 원리(principle of locality)를 활용해서 가능한 많은 메모리를 가장 빠른 기술의 속도로 가장 싼 기술로 사용 가능하도록 유저에게 제공하는 것이다. 빠르고 작은 메모리부터 크고 느린 순서대로 나열하면 다음과 같다.
| on-chip component | second level cache | Main Memory | Secondary Memory | |
| datapath 내 Register File | ITLB/DTLB 및 ICache, DCache | SRAM | DRAM | Disk (SSD 등) |
| 비쌈, 작음, 빠름 --------------------------------------------------------------------------------------------------- 쌈, 큼, 느림 | ||||
다음과 같이 메모리 구성요소별로 다양한 위계가 존재한다. 아키텍처 관점에서는 캐시와 메인 메모리 간의 위계를 다룬다.
- 레지스터 ↔ 메모리: 컴파일러에 의해 처리됨
- 캐시 ↔ 메인 메모리: 캐시 컨트롤러 하드웨어에 의해
- 메인 메모리 ↔ 디스크: OS(VM)에 의해 - TLB
지역성(Locality)
메모리 위계는 어떻게 작동하는가? 다음 두 가지의 지역성이 주요 원인이다.
- 시간적 지역성 Temporal Locality: 이전에 접근된 메모리 위치가 곧 다시 접근될 것이라는 특성 → 최근에 접근된 데이터를 프로세서 근처에 위치시킨다.
- 공간적 지역성 Spatial Locality: 접근된 메모리 근처의 메모리가 곧 접근될 것이라는 특성 → 연속적인 word로 구성된 block(즉 VM에서 연속적인 데이터 item)을 프로세서 근처에 위치시킨다.
지역성은 프로그램 종류에 따라 다르다. 스택 내 데이터에서 돌아가는 작은 loop의 경우 지역성을 많이 활용할 것이고, 거의 랜덤한 subroutine을 빈번하게 호출하거나 대규모 sparse 데이터 셋을 순회(reuse 없는 랜덤 데이터 접근)하는 프로그램의 경우 지역성을 많이 활용하지 않는다. 하지만 대부분의 프로그램은 어느 정도의 지역성을 띠고 있다.
2. 캐시
이제 캐시와 메인 메모리 간 위계가 어떻게 구성되어 있는지 알아보자.

왼쪽 그림과 같이 캐시는 프로세서와 메인 메모리 사이에 위치하여 데이터를 저장하는 역할을 한다.
메인 메모리에서 캐시로 데이터를 복사해올 때는 Block(=cacheline) 단위로 진행되며, 보통 32B, 64B, 128B로 여러 word로 구성된다.
만약 접근된 데이터가 캐시에 존재한다면 Hit, 캐시에 없다면 Miss라 한다. Miss의 경우 메모리(혹은 더 낮은 레벨의 캐시)에서 해당 데이터를 포함하는 블록을 복사(즉, 공간적 지역성 spatial locality 활용)해온다. 이때 소요되는 시간을 miss penalty라 한다.
- Hit ratio: hits/전체 접근
- Miss ratio: misses/전체 접근 = 1-hit ratio
캐시는 하드웨어에 의해 관리되며, 대부분 빠른 SRAM을 기반으로 만들어진다. (하지만 DRAM도 캐시가 될 수 있긴 하다.)
캐시 조직은 다음과 같이 이루어진다.
- 데이터 단위: cache block (Cacheline)
- 데이터를 캐시에 채워 넣는 것: miss handling
- 캐시에서 데이터를 찾는 것: address mapping → 인덱싱과 태그 매칭을 통해서 정확한 주소를 찾는다.
e.g. 인텔 코어 i7 캐시는 코어별로 분리된 L1 i-cache와 d-cache(32KB, 8-2ay, 접근 4 cycle 소요), 각 코어 내에서 공유되는 L2 cache(256KB, 8-way, 접근 11 cycle), 그리고 코어 간 공유되는 L3 캐시(8MB, 16-way, 30~40 cycle)의 3-level로 구성된다. 블록 크기는 64B이다.
캐시에 데이터를 쓸 때 두 가지 전략이 존재한다. 이는 캐시 일관성 문제(cache coherence)와 관련이 있다.
- Write-through: 캐시에 데이터를 쓰는 순간 동시에 lower levels에도(하위 레벨의 캐시, 메인메모리) 동시에 데이터를 업데이트하는 것
- Write-back: 업데이트된 블록이 대체될(replacement, evict) 때만 lower levels에 업데이트하는 것 (즉, dirty bit set일 때만)
이 두 전략은 모두 비동기적 write을 위해 write buffer를 사용한다.
캐시 배치 정책
set의 개수(즉, 하나의 인덱스로 몇 개의 가능한 데이터(주소)를 저장할 것인지)에 따라 direct-mapped cache(set당 하나의 block, 즉 1-way인 경우), n-way set associative cache(하나의 set에 n개의 데이터 저장), fully associative cache(인덱스 없이 태그만 사용, 1개의 set, ways 수는 캐시 라인 수와 동일)로 나뉠 수 있다.
* set: 캐시 내 캐시라인의 그룹 / way: 데이터와 태그를 포함하는 개별 캐시라인. 즉 set당 저장하는 데이터 수 = way 수
※ 과제 내용 복습
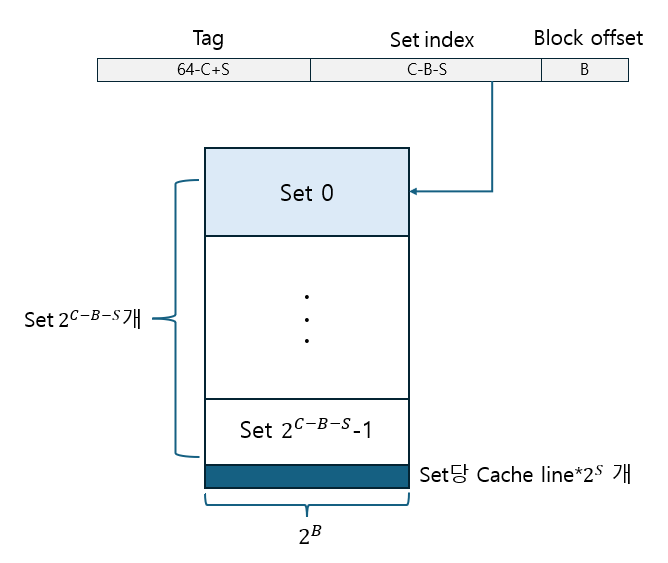
2^C Byte의 데이터를 저장하고, 2^B byte block, 셋 당 2^S개의 블록을 갖는 캐시 시스템 w/ 64-비트 주소.
→ 64bit 주소 중 상위 64-C+S는 tag bit, 그 다음 C-B-S는 index bit, 마지막 하위 B bit는 block offset으로 사용한다. set은 총 2^C-B-S개가 되고, set당 캐시라인(블록)은 주어진 것과 같이 2^S개이다.
즉 2^C-B-S 개의 set, 2^S-way 인 캐시인 것이다. 총 데이터는 #set * #cachelines/set * block size = 2^C-B-S * 2^S * 2^B = 2^C로 주어진 것과 동일하다.
Direct-mapped Cache
각 주소별로 저장할 수 있는 위치가 하나인 캐시. set당 way가 1인 경우이다. 빠르지만, 같은 index를 갖는 주소가 여러 개인 경우 계속해서 서로를 evict하게 되어 성능이 떨어질 수 있다. 이를 해결하기 위해 associative cache를 사용한다.

Associative cache
같은 index를 갖는 여러 주소가 존재하는 경우 여러 개의 데이터를 저장할 수 있도록 한 캐시 구조이다. set당 n개의 데이터를 저장할 수 있는 경우 n-way set associative cache라 한다. n이 클수록 같은 인덱스를 갖는 더 많은 서로 다른 주소가 저장될 수 있다. 극단적으로, 주소 전체를 태그로 사용하여 서로 다른 주소는 항상 서로 다른 위치에 데이터를 저장하도록 하는 fully-associative cache도 존재한다. 이 경우 set은 1개이며 way의 수는 전체 캐시라인 수와 동일하다.


캐시 대체 정책 Cache Replacement Policy
Fully associative cache를 제외하고, direct-mapped cache나 set associative cache의 경우 캐시의 저장하고자 하는 주소에 데이터가 다 차 있다면 이미 존재하는 데이터를 새 것으로 대체해야 한다. direct-mapped cache의 경우 데이터 1개만 존재하므로 그 데이터를 빼 버리면 된다. 하지만 set associative cache에는 여러 개의 데이터가 존재하므로, 그 중 어느 것을 evict할지 정해야 한다.
| LRU | Random |
| - temporal locality 활용 - 2-way에서는 1bit만 활용하면 되므로 간단하지만, way 수가 늘어날수록 데이터 간 접근 순서를 저장해야 하므로 복잡해진다. - locality assumption이 적용되지 않는 상황인 경우 오히려 안 좋을 수 있음 |
높은 associativity (*associativity = set의 크기, 즉 set당 ways 수)의 캐시인 경우 LRU와 비슷한 성능을 보임 |
캐시 미스의 종류
크게 네 종류의 캐시 미스가 있다.
- Compulsory Miss: 해당 블록을 첫 번째로 접근하는 경우 발생하는 miss. cold miss라고도 하며 prefetch로 해결할 수 있다.
- Capacity Miss: 캐시 용량으로 인한 미스. 같은 용량의 fully associative cache에서도 발생할 수 있는 미스. 블록이 폐기된 후 나중에 다시 회복되는 경우.
- Conflict Miss: 캐시의 같은 곳에 위치하는 여러 주소의 서로 다른 블록을 반복적으로 접근하는 경우. associativity늘 늘려서 해결할 수 있음.
- Coherence Miss: 일관성 invalidation으로 인해 발생
캐시 메트릭
캐시의 성능을 측정할 수 있는 메트릭에 대해 알아보자. 평균 메모리 접근 시간은 다음과 같이 계산된다.
AMAT(Average Memory Access Time) = Hit latency + Miss rate * Miss Latency
- hit latency: 보통 L1 캐시는 1~3 사이클, L2 캐시는 8~20 사이클 정도이지만 더 다양한 latency를 가질 수 있다.
- miss rate: 캐시 미스 수 / 전체 캐시 접근 수 = 1 - hit rate
- miss latency: 다음 레벨의 캐시나 메인 메모리에서 데이터를 fetch해오는 데 걸리는 시간
예를 들어, 70%의 hit, hit은 1 cycle 소요, 메인 메모리 접근은 25 사이클 소요되는 어떤 캐시가 있다면, 이 경우의 AMAT는 다음과 같이 구할 수 있다.
AMAT = 1 + (1-0.7)*25 = 8.5 cycle
*주의: miss latency는 1(L1)+25(main)이 아닌 25(main) 사이클임!
캐시 최적화 방법
캐시 성능을 향상시킨다는 것은 곧 AMAT를 줄인다는 것을 의미한다. hit latency를 줄이거나(더 작은 캐시), miss rate을 줄이거나(더 큰 캐시), miss latency를 줄일(더 좋은 lower-level cache/메모리 접근 시간) 수 있다. → factor들 간 tradeoff가 존재한다. 기초적인 6가지 캐시 최적화 방법에 대해 알아보자.
| 1. 블록 크기 늘리기 | - 프리페칭 효과로 compulsory miss를 줄일 수 있음 - 캐시 용량 늘릴 수 있지만, conflict miss와 miss penalty도 늘리게 됨 |
| 2. 전체 캐시 용량 늘리기 | - miss rate을 줄일 수 있음 - hit time과 전력 소비도 늘리게 됨 |
| 3. associativity 늘리기 | - conflict miss를 줄일 수 있음 - hit time과 전력 소비도 늘리게 됨 |
| 4. 캐시 레벨 수 늘리기 | - 전반적인 메모리 접근 시간을 줄임 |
| 5. write miss보다 read miss에 우선순위 부여 | - miss penalty를 줄일 수 있음 *in-order에서는 write 때문에 나머지가 stall되며, read가 write보다 더 critical하기 때문.(read 없이는 다음 단계로 진행이 안 됨) ** Out-of-order에서는 write은 버퍼링되었다가 한 번에 commit되고, read는 커밋보다 더 빠르게 진행됨 |
| 6. 캐시 인덱싱 시 주소 변환 피하기 | - hit time을 줄일 수 있음 |
하지만 이 전략들도 서로 간에 trade-off가 있는 것을 확인할 수 있다.
다층 캐시 Multi-level caches
대부분의 고성능 프로세서는 다층 캐시를 가진다. (locality를 통해서 성능을 높일 수 있기 때문) L1은 instruction cache와 data cache로 분리하고, L2와 L3은 unified cache로 사용한다.
다층 캐시에서의 AMAT는 다음과 같이 계산할 수 있다. 예시는 2-level cache인 경우이다.
AMAT = Hit_Latency_L1 + Miss_Rate_L1 * (Hit_Latency_L2 + Miss_Rate_L2 * Miss_Latency_L2)
*이때 Hit_Latency_L2 + Miss_Rate_L2 * Miss_Latency_L2는 Miss_Latency_L1이다.
다층 캐시에서 데이터를 저장하는 경우, 데이터를 서로 어떻게 저장하는지에 따라 inclusive와 exclusive로 나눌 수 있다.
어떤 프로세서가 L1, L2 2-level 캐시를 가진다고 해 보자.
Inclusive Caches (completely inclusive)
- 만약 블록 A가 L1에 존재한다면 A는 L2에도 반드시 존재해야 한다. 즉 L1은 항상 L2의 부분집합이다.
- L1 miss 발생 시 L1과 L2 모두 채워진다.
- L2의 블록에 대한 eviction이나 invalidation 발생 시 L1에서도 같은 블록에 대해 동일하게 invalidate한다.
- L2가 L1보다 매우 큰 경우에만 성립함 (e.g. 2배 정도밖에 차이 나지 않는 경우 inclusvie cache는 L2의 공간을 낭비하게 된다.)
Exclusive Caches (completely exclusive)
- 블록은 한 번에 하나의 캐시에만 존재할 수 있다.
- L1 miss 발생 시 L1 캐시만 채워지며,
- L1 eviction 시 해당 victim block은 L2로 보내진다.
- L2는 L1에 대한 victim buffer가 되는 것이다.
- 여러 레벨의 캐시 간에 중복되는 복사본이 없으므로 용량을 절약할 수 있다.
- 하지만 coherence 문제가 발생할 수 있다.
이외에도 덜 strict한 inclusive/exclusive 캐시가 존재한다. e.g. partially-inclusive cache



