
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- pipelined cache
- pipline hazards
- cache coherence miss
- cache coherence
- theta join
- nonblocking cache
- atomic exchange
- store conditional
- load linked
- sql
- directory based coherence protocol
- cache optimization
- Subquery
- multibanekd cache
- moesi
- dependence
- Cache
- 관계형 모델
- dynamic scheduling
- pipelined
- structural hazard
- way prediction
- branch prediction
- sequential consistency
- relational model
- register renaming
- speculative execution
- transactional memory
- ISA
- mesi
- Today
- Total
공대생의 공부흔적
[컴퓨터구조#11-2] 캐시 일관성 (Cache Coherence) - 캐시 일관성 미스, 다층 캐시, 디렉토리 기반 프로토콜 본문
[컴퓨터구조#11-2] 캐시 일관성 (Cache Coherence) - 캐시 일관성 미스, 다층 캐시, 디렉토리 기반 프로토콜
생대공 2024. 6. 5. 23:14참고: Computer Architecture: A Quantitative Approach (5th edition) - 5.4.
지난 글에 이어, 캐시 일관성에 대한 추가적인 주제들을 다룰 것이다.
목차
- 캐시 일관성 미스
- 다층 캐시
- 디렉토리 기반 프로토콜
1. 캐시 일관성 미스
일반적으로 캐시 미스에는 cold, capacity, conflict 세 가지의 미스가 존재한다.
하지만 invalidation 기반 멀티프로세서에만 있는 새로운 캐시 미스의 종류가 존재한다. 예를 들면 다음과 같다.
- P1 read address A (S state)
- P2 write to address A (P1은 I state, P2는 M state)
- P1 read address A → 이때 invalidation으로 인해 캐시 미스가 발생한다.
이러한 coherence miss는 true and false sharing에 의해 발생한다.
True sharing
producer는 새로운 값을 생성하고(동시에 consumer의 캐시에 있는 copy는 무효화), consumer는 그 새로운 값을 읽는다.
False sharing
- 업데이트된 부분이 실제로 사용되지 않더라도 블록은 invalidate될 수 있다.
- invalidation의 단위는 캐시 블록이다. 즉, 캐시 블록의 일부만 업데이트되더라도 전체 블록을 invalidate해야 한다.
- 만약 P1, P2 두 개의 프로세서가 동일한 캐시 블록의 서로 다른 부분에 write하는 경우 어떻게 될까?
- P1과 P2는 반복해서 캐시 내의 캐시블록을 invalidate할 것이다. 이러한 상황이 false sharing이며, 성능을 심각하게 저하시킨다.
- 이러한 false sharing의 해결방안은 다음과 같다.
- 소프트웨어: 프로그래머가 false sharing을 피하기 위해 데이터 구조를 적절히 align한다.
- 하드웨어: sub-blocking이 가능하나 복잡하다. 보통 소프투웨어 차원의 솔루션으로 충분하다.
*Snoopy-bus with switched networks
일반적인 공유 wire를 갖는 physical bus는 잘 scale하지 못한다. 따라서, 트리 기반의 주소 네트워크나 링 기반의 주소 네트워크를 사용할 수 있다. -> 잘 broadcast하기 위함
이러한 snoop 기반의 프로토콜은, (1) broadcasting mechanism과 (2) serialization mechanism 두 가지가 꼭 필요하다. 이는 아래 AMD HyperTransport 예시에서 더 자세히 알아볼 것이다.
2. 다층 캐시
캐시 coherence에서는 반드시 물리 주소를 사용해야 하므로, 캐시는 물리적으로 tagged되어야 한다.
L1,L2로 이루어진 2-level 캐시를 생각해보자.
- inclusion property가 없는 경우: L1과 L2는 모두 snoop해야 함.
- L1이 L2에 완전히 포함되는 경우(with complete inclusion property): L2 캐시만 먼저 snoop하고, 만약 L2에서 snoop hit 발생 시 해당 snoop 요청을 L1으로 포워딩한다. L2에서 캐시 미스라면 L1에서도 캐시 미스이기 때문이다.
L1이 수정된 복사본을 가지고 있는 경우, 해당 데이터는 L2로 flush down된 후 다른 캐시로 보내져야 한다.
예시: AMD HyperTransport
특징
- Snoop-based coherence with NUMA (Non-Uniform Access Time)
- snoop 기반이지만, home node를 serialization point로 삼은 (packet 기반의) point to point network임 -> 디렉토리 기반 프로토콜과 유사
- on-chip coherence와 interconnection 컨트롤러를 통합
- 주소와 데이터 패킷을 위해 공유되는 네트워크

이 AMD HyperTransport가 home node(DRAM에 물리 주소가 맵핑된 노드. 물리 주소에 의해 정적으로 정해짐.)를 통해 앞서 언급한 두 가지 메커니즘을 어떻게 만족하는지 알아보자.
- Broadcast mechanism: 각 요청은 home node로 먼저 보내진 후, 이 home node가 다른 모든 노드에 메시지를 broadcast함.
- Serialization mechanism: home node 개념 도입
- (home node 개념 없는 경우) 2개의 코어가 동시에 같은 주소(A)에 대해 readRFO 발행 시 무엇이 먼저인지 정할 수 없음.
- (home node 도입 후) A가 저장된 메모리의 home node에 더 먼저 도착한 요청 기준으로 serialization이 가능하다. 즉, home node를 통해 같은 주소에 대한 겹치는 요청은 순서를 정할 수 있게 된다(can serialize the accesses).
*이러한 home node를 통한 serialization은 각 node가 요청을 직접 broadcast하지 못하고, 일단 home node에 먼저 보낸 후 home node를 통해서만 broadcast할 수 있다는 단점이 있다. 이를 완화하기 위해, speculative technique에서는 conflict. 즉 같은 주소에 대한 coherence transaction이 매우 infrequent하게 발생한다고 가정하여 각 노드에서 home node로 요청을 보내지 않고 requester가 직접 broadcast할 수 있도록 한다. 이때 home node는 conflict가 있는지 확인하는 역할을 하게 되며, 만약 conflict가 있는 경우 requester가 보낸 그 요청을 무시하고 home node가 다시 serialization을 맡아서 해당 요청을 broadcast하게 된다.
3. 디렉토리 기반 프로토콜
캐시 일관성 시스템은 반드시...
- 여러 state, state 전환 다이어그램, 그리고 action을 제공해야 한다.
- 일관성 프로토콜 관리 방법
- 일관성 프로토콜을 언제 invoke할지 → 모든 시스템에서 같은 방법으로 진행됨. (캐시 내에 각 line에 대한 state가 저장되며, 해당 line에서 access fault 발생 시 프로토콜이 invoke됨.)
- (a) action을 정하기 위해 다른 캐시 안의 block에 대한 state 정보를 찾아야 함
- (b) 다른 copy를 어디에 둘지
- (c) 해당 copy들과 어떻게 통신할지 (비활성화/업데이트)
Bus 기반 coherence에서는, (a)~(c)는 모두 bus를 통한 broadcast를 통해 이루어진다. 개념상 간단하지만 bus 대역폭이 증가하지 않는 이상 프로세서 개수에 대해 scalable하지 않다. scalable한 coherence는, 모든 fault는 적어도 p(=#processor)개의 네트워크 트랜잭션을 일으키게 된다. scalable coherence에서는 같은 캐시 state와 state transition diagram을 갖리 수 있고, 프로토콜을 관리하기 위한 서로 다른 메커니즘이 있어야 한다.
→ scalable한 접근: 디렉토리. 디렉토리에서는 모든 메모리 블록이 관련된 디렉토리 정보를 가지고, 캐시블록의 copy와 그 state에 대한 정보를 계속 트래킹한다. 미스 발생 시, 디렉토리 entry를 찾아 lookup하고, 필요한 경우 해당 copy를 가진 노드하고만 통신하면 된다. scalable한 네트워크에서 디렉토리와 copy 간 통신은 네트워크 트랜잭션을 통해 이루어진다.
디렉토리의 기본 작동 방식
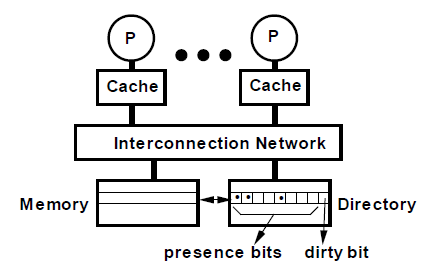
- k 개의 프로세서가 있다고 해보자.
- 메모리 내 각 캐시 블록은 k개의 presence bit와 1개의 dirty bit을 가진다. 즉, directory entry는 시스템의 모든 메모리 블록에 대해 존재해야 한다.
- 캐시 내의 각 캐시 블록은 1개의 valid bit과 1개의 dirty(owner) bit을 가진다.
- 항상 모든 캐시에 요청을 보내는 snoop 기반의 프로토콜과 달리, 디렉토리 기반 방식에서는 디렉토리 컨트롤러가 각 메모리 블록의 shared state를 tracking하여 어떤 코어가 캐시를 갖고 있는지 확인하고, 필요한 코어에만 요청을 보낸다.
processor i에 의해 메인 메모리에서의 읽기 요청이 들어오면:
1) dirty-bit OFF: 메인 메모리에서 읽어오고, p[i] ON (*p[i]: processor i의 presence bit)
2) dirty-bit ON: dirty proc에서 line을 불러옴(& 캐시 state는 shared로), 메모리 업데이트, dirty bit OFF, 불러와진 데이터를 i로 보냄
각 캐시라인에 대해, 캐시의 경우 기존 MSI 프로토콜과 동일한 S/I/M 3개의 state를 가지며 디렉토리의 경우 S/U/M 세 가지의 state를 가진다.
| S (Shared) | 1개 이상의 프로세서가 데이터를 갖고 있으며, 메모리는 up-to-date |
| U (Uncached) | 어떤 프로세서도 데이터를 갖고 있지 않음. 어떤 캐시에서도 valid하지 않음. |
| M (Modified) | 1개의 프로세서(owner)가 데이터를 갖고 있으며, 메모리는 out-of-date |
캐시 state에 더해, 디렉토리 프로토콜은 shared state에 있을 때 어떤 프로세서들이 데이터를 가지고 있는지를 계속 확인하고 있어야 한다.
또한, 디렉토리 프로토콜의 동작과 관련된 새로운 노드 용어들이 있다: 요청이 시작되는 local node, 해당 주소가 있는 메모리 위치와 가장 가까운 home node, 그리고 exclusive거나 shared의 상태로 캐시블록의 복사본을 가진 remote node이다.
