
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- sequential consistency
- pipelined cache
- theta join
- Cache
- load linked
- way prediction
- nonblocking cache
- speculative execution
- cache coherence miss
- multibanekd cache
- atomic exchange
- moesi
- 관계형 모델
- structural hazard
- mesi
- dependence
- transactional memory
- directory based coherence protocol
- ISA
- pipelined
- relational model
- register renaming
- cache coherence
- dynamic scheduling
- Subquery
- store conditional
- cache optimization
- sql
- branch prediction
- pipline hazards
- Today
- Total
공대생의 공부흔적
[컴퓨터구조#1-1] ISA(Instruction Set Architecture, 명령어 집합 구조)의 원리 알아보기 - ISA 분류/Memory Addressing/피연산자의 종류와 크기 본문
[컴퓨터구조#1-1] ISA(Instruction Set Architecture, 명령어 집합 구조)의 원리 알아보기 - ISA 분류/Memory Addressing/피연산자의 종류와 크기
생대공 2024. 3. 10. 17:04참고: Computer Architecture: A Quantitative Approach (5th edition) - Appendix A. Instruction Set Principles
컴퓨터 구조 파트의 첫 번째 주제는 ISA이다. Computer Architecture: A Quantitative Approach (5th edition)의 부록 A를 바탕으로 ISA의 원리를 간단하게 복습해보고자 한다. 책에서와 같이 다음 목차에 따라 구성되며, 이번 글에서 1~3을, 다음 글들에서는 각각 4~6, 7~8을 다룰 것이다.
목차
- ISA 분류하기
- Memory Addressing
- 피연산자의 종류와 크기
- Instruction Set에서의 연산(Operations)
- Control Flow를 위한 명령어
- 명령어 집합 인코딩
- 컴파일러의 역할
- MIPS 아키텍처
1. ISA 분류하기
ISA(Instruction Set Architecture)는 프로그래머나 컴파일러 작성자에게 visible한 컴퓨터의 부분이다. 하드웨어/소프트웨어 인터페이스의 기본적인 요소로서, 크게 해당 명령어가 무엇을 해야 할지 나타내는 opcode와 연산의 대상이 되는 operand(피연산자)로 구성되어 있다.
프로세서의 내부 스토리지 유형은 가장 기본적인 차이점이다. 이에 따라 크게 Stack, Accumulator, 또는 Register 세트로 분류할 수 있고, 종류에 따라 피연산자는 명시적으로 혹은 암시적으로 명명된다. - stack architecture에서 피연산자는 암시적으로 stack의 가장 위에 위치하게 되고, accumulator architecture에서는 하나의 피연산자는 암시적으로 accumulator 그 자체이다. general-purpose register architecture만 명시적인 피연산자를 갖는데, 이때 피연산자의 위치에 따라 register-memory와 register-register로 나눌 수 있다. 그림엔 없지만 최근에는 모든 피연산자가 메모리에 저장되는 memory-memory 아키텍처도 있다. 또한, 단일 accumulator보다 많은 수의 레지스터를 사용하지만 해당 레지스터에 제한을 걸게 되는 extended accumulator(혹은 special-purpose register) 아키텍처도 존재한다.

이를 바탕으로, C=A+B라는 코드 시퀀스를 수행하는 경우, 각 ISA 유형별로 어떤 과정을 거치는지 다음과 같이 정리해볼 수 있다.
| Stack | Accumulator | Register (register-memory) |
Register (load-store) |
| Push A | Load A | Load R1, A | Load R1, A |
| Push B | Add B | Add R3, R1, B | Load R2, B |
| Add | Store C | Store R3, C | Add R3, R1, R2 |
| Pop C | Store R3, C |
초기 컴퓨터들은 stack 아키텍처나 accumulator 아키텍처를 사용했지만, 1980년대 이후 제작된 모든 아키텍처는 load-store 아키텍처(register-register)를 사용하고 있다. 이러한 일반 목적의 레지스터 컴퓨터(General-purpose register computer, GPR)이 등장하게 된 이유는 다음과 같이 정리할 수 있다.
- 레지스터는 메모리보다 빠르다.
- 레지스터는 다른 형태의 내부 스토리지보다 컴파일러가 사용하기에 효율적이다.
- (예시) (A*B)-(B*C)-(A*D)를 계산하는 레지스터 컴퓨터는 곱 연산을 어떤 순서로도 처리할 수 있다. 이는 피연산자의 위치 혹은 파이프라이닝으로 인한 더 높은 효율성을 가져올 수 있다. 반면 stack 아키텍처의 경우 피연산자가 스택에 숨겨져 있기 때문에 하나의 순서로만 계산해야 하므로 피연산자를 여러 번 로드하게 된다.
- (★ 가장 중요 ☆) 레지스터는 변수 값을 들고 있을 수 있다. 변수가 레지스터에 할당될 때, 메모리 트래픽이 감소하여 프로그램이 가속될 수 있고(레지스터 접근이 메모리보다 빠르기 때문), 결과적으로 코드 밀도도 향상된다(레지스터는 메모리 위치보다 적은 비트 수로 이름 붙여질 수 있다).
GPR 아키텍처를 나누는 두 가지 주요 특징이 있다. (1) ALU 명령어가 몇 개의 피연산자를 가지는지(2개/3개), (2) ALU 명령어에서 메모리 주소가 될 수 있는 피연산자의 개수(0~3개)이다. 이 두 가지 특징을 바탕으로 load-store, register-memory, memory-memory 세 종류로 기존 컴퓨터 아키텍처를 분류할 수 있다.
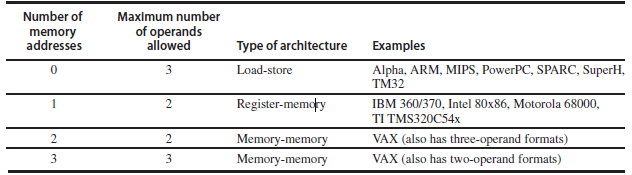
각 종류별로 갖는 장점과 단점을 다음과 같이 분류할 수 있다.
| 종류 | 장점 | 단점 |
| Register-register (0,3) |
단순하고 고정된 길이의 명령어 인코딩이 가능. 간단한 코드 생성 모델. 명령어 실행 시 더 적은 수의 clock cycle 사용. |
메모리를 참조하는 아키텍처보다 명령어 개수가 많음. → 많은 명령어 개수와 낮은 명령어 밀도는 프로그램을 더 크게 만든다. |
| Register-memory (1,2) |
별다른 로드 명령어 없이 데이터에 접근 가능. 명령어 형식이 인코딩하기 쉬우며 따라서 좋은(=낮은) 밀도 달성 가능. |
이진 연산에서 src 피연산자가 파괴되기 때문에 피연산자들이 모두 동일하지 않음. 레지스터 수와 메모리 주소를 각각의 명령어로 인코딩하는 것은 레지스터 개수를 제한할 수 있음. 명령어 당 clock 사이클이 피연산자 위치에 따라 달라짐. |
| Memory-memory (2,2) 혹은 (3,3) |
가장 컴팩트하며, 임시 값을 위해 레지스터를 낭비하지 않음. | 특히 3개 피연산자를 사용하는 경우 명령어 크기가 일정하지 않음. 명령어당 해야 할 일의 시간이 다양함. 메모리 접근이 병목을 일으킴. (오늘날에는 사용되지 않음) |
물론 이러한 장단점은 어디까지나 질적인 것이고 실제 영향은 컴파일러와 구현 전략에 따라 다르다. 가장 보편적인 아키텍처의 영향 중 하나는 명령어 인코딩과 작업 수행에 필요한 명령어의 수에 있다. (이후 파이프라인에서 다룰 것)
2. Memory Addressing
아키텍처의 종류(load-store, memory 참조 여부)에 상관없이, 메모리 주소가 어떻게 해석되고 지정되는지는 정의되어야 한다.
메모리 주소 해석하기
메모리 주소는 어떻게 해석되는가? 즉, 어떤 오브젝트가 주소와 길이의 함수로 접근되는가? 해당 책(이번 글)에서 논의되는 모든 명령어 집합은 바이트 단위로 주소를 지정하며, 바이트(8 bit), 반 워드(16 bits), 그리고 워드(32 bits) 단위의 접근을 제공한다. 대부분의 컴퓨터는 더블 워드(64 bits)에 대한 접근도 제공한다.
바이트 순서: Little/Big Endian
더 큰 객체 내의 바이트 순서는 Little Endian 혹은 Big Endian으로 위치시킬 수 있다.
- Little Endian: 주소가 "x...x000"인 바이트를 더블 워드의 가장 낮은 자리에 위치시키는 방법. 바이트 번호는 다음과 같다.
7 6 5 4 3 2 1 0- Big Endian: 주소가 "x...x000"인 바이트를 더블 워드의 가장 높은 자리에 위치시키는 방법. 바이트 번호는 다음과 같다.
0 1 2 3 4 5 6 7하나의 컴퓨터 내에서 작동할 때는 보통 바이트 순서가 눈에 띄지 않는다. 하지만 서로 다른 순서를 사용하는 컴퓨터 간에 데이터를 교환할 때는 문제가 된다. 가령 Little Endian은 문자열을 비교할 때 일반적인 단어 순서와 반대로 구성된다. (e.g. BACKWARDS → SDRAWKCAB)
메모리 주소에 Align
두 번째 메모리 이슈는 바이트보다 큰 오브젝트에 대한 접근은 반드시 정렬되어야 한다aligned는 것이다. s만큼의 크기를 갖는 오브젝트에 대한 접근은 A mod s = 0인 경우 바이트 주소 A에 align된다.

일반적으로 메모리는 워드 혹은 더블워드의 배수에 맞춰 정렬되기 때문에, 정렬되지 않은 상태Misalignment는 하드웨어 복잡성을 일으키게 된다. 따라서 정렬되지 않은 메모리 접근은 여러 번의 정렬된 메모리 접근을 유발한다. 즉, 비정렬 접근을 허용하는 컴퓨터에서조차도 정렬된 접근을 하는 프로그램이 더 빨리 돌아간다.
데이터가 정렬되어 있더라도, 바이트, 반워드, 워드 접근을 지원하려면 64-bit 레지스터에서 바이트, 반워드, 워드를 정렬하는 네트워크가 필요하다. 예를 들어 위 그림에서 3개의 최하위 비트 값이 4인 주소(오른쪽에서 4번째 열)에서 바이트를 읽는다면 바이트를 64-bit 레지스터의 적절한 곳에 위치시키기 위해 오른쪽으로 3 바이트만큼 shift시켜야 할 것이다. 명령에 따라서 부호를 확장해야 할 수도 있고, 컴퓨터에 따라 바이트, 반워드, 워드 연산이 레지스터의 상위 부분에는 영향을 주지 않을 수도 있다.
주소 모드(Addressing Modes)
주소 모드: 명령어에 의해 주소가 지정되는 방식
주소가 주어졌을 때, 이제 우리는 메모리의 어떤 바이트에 접근해야 하는지 안다. 주소 모드란, 어떻게 아키텍처가 접근할 오브젝트의 주소를 지정하는지에 관한 것이다. 주소 지정 모드는 메모리 내에서의 주소뿐만 아니라 상수와 레지스터도 지정한다. 메모리 주소가 사용될 때, 주소 모드에 의해 실제로 지정되는 주소는 effective address라 불린다. 다음 표는 최근 컴퓨터에 의해 사용되는 데이터 주소 모드를 보여준다.
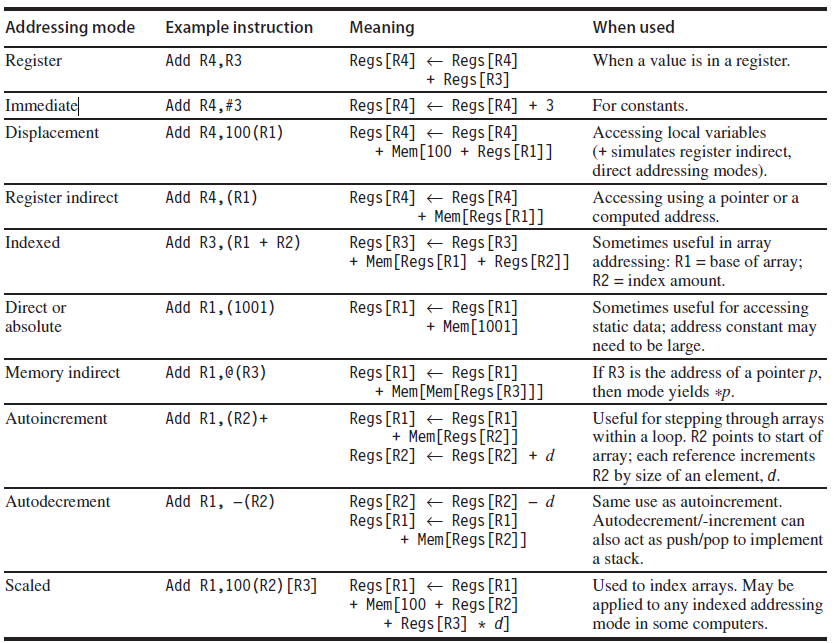
Immediates 혹은 Literals는 보통 메모리 주소 모드로 생각된다. 레지스터가 보통 분리되어 메모리 주소가 필요 없음에도 불구하고 말이다. 보통 주소 모드를 프로그램 카운터에 관련된 것(PC-relative addressing)으로 분리하여 생각하고 있기 때문이다. PC-관련 주소는 주로 컨트롤 전달 명령어에서 코드 주소를 지정할 때 사용된다.(5. Control Flow를 위한 명령어에서 다룰 것)
주소 모드는 명령어 숫자를 상당히 줄일 수 있지만, 컴퓨터 구축의 복잡도와 명령어당 클럭 사이클을 증가시킬 수 있다. 따라서 다양한 주소 모드를 사용하는 것은 설계자가 무엇을 포함할지 고르는 데 상당히 중요하다. 다음 그림은 VAX 아키텍처에서 3가지 종류의 프로그램을 사용하는 경우 주소 모드 패턴이다. Immediate와 Displacement가 대부분의 주소 모드 사용량을 차지하는 것을 확인할 수 있다.
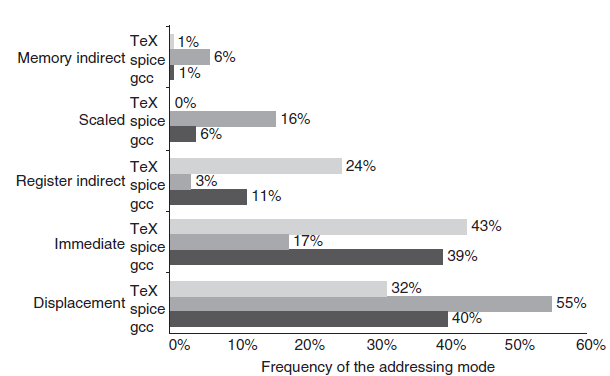
Displacement 주소 모드
Displacement-스타일의 주소 모드와 관련된 주요 질문은 displacement가 사용되는 범위이다. 다양한 displacement 크기의 사용에 기반하여 어떤 크기를 지원해야 할지 정할 수 있다. Displacement 필드 크기를 정하는 것은 명령어 길이에 직접 영향을 주기 때문에 중요하다.
저자들의 벤치마크 프로그램을 사용한 경우 load-store 아키텍처에서 발생한 데이터 접근

Immediate/Literal 주소 모드
Immediate는 수학 연산, 비교(브랜치 연산), 레지스터 내 상수 이동에 사용될 수 있다. Immediate를 사용하는 경우 이들이 모든 연산에 대해 지원되어야 할지 혹은 subset에 대해서만 지원되어도 되는지 알 필요가 있다. 또한, displacement와 마찬가지로 immediate 값은 다양한 크기를 가질 수 있고, 이는 명령어 길이에 영향을 준다. 보통 작은 immediate 값들이 가장 많이 사용되고, 큰 값들은 보통 주소 계산에 가끔 사용된다.
Immediate value들의 분포
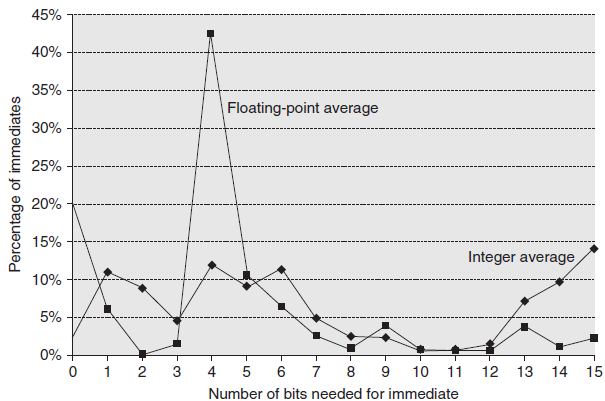
요약해보면, 위 VAX 사용 패턴 그래프를 바탕으로 (1) 적어도 Displacement, Immediate, Register Indirect 세 종류의 주소 모드를 포함해야 한다. (2) Displacement 모드에 사용될 주소 비트는 적어도 12에서 16 비트는 되어야 한다. (3) Immediate 필드에 사용될 크기는 최소 8에서 16 비트가 되어야 한다.
지금까지 ISA 종류를 살펴본 후 register-register 아키텍처를 선택하고, 데이터 주소 모드에 대한 추천사항을 살펴보았으니, 이제 데이터의 크기와 의미에 대해 알아볼 차례이다.
3. 피연산자의 종류와 크기
피연산자 유형 지정에서 가장 일반적으로 사용되는 방법은 opcode에서 인코딩되는 것이다. 혹은 하드웨어에서 해석되는 태그가 추가되어 태그를 통해 피연산자 유형 지정 및 연산 선택을 수행할 수도 있는데, 이러한 방법을 사용하는 컴퓨터는 박물관에서나 찾아볼 수 있다.
데스크탑과 서버 아키텍처에서, 보통 피연산자의 종류(정수, single-precision floating point, character 등)는 효과적으로 해당 크기를 나타낸다. 일반적으로 사용되는 피연산자 유형은 다음과 같다.
- character (8 bits)
- half word (16 bits)
- word (32 bits)
- single-precision floating point (1 word = 32 bits)
- double-precision floating point ( 2 word = 64 bits)
정수는 보통 2의 보수 이진수로, 문자는 ASCII로 표현되나 최근 자바에서 사용되는 16-bit Unicode가 인기를 얻고 있다. 어떤 아키텍처는 문자열에 대한 연산을 제공하기도 하지만, 보통 이런 연산들은 제한되어 있으며 문자열을 단일 문자로 취급한다. 문자열에 적용되는 일반적인 연산은 비교(comparison)과 이동(move)이다.
비즈니스 응용에서 어떤 아키텍처는 packed decimal 혹은 binary-coded decimal이라 불리는 decimal 포맷을 지원한다. 4 비트로 0~9를 표현하고 2개의 decimal digit이 각 바이트에 들어간다. decimal 피연산자를 사용하는 이유 중 하나는 결과를 정확히 decimal로 얻기 위해서이다. 어떤 decimal 분수는 정확히 대응되는 이진수가 없기 때문이다. (e.g. 0.10_10은 이진수로 표현 시 무한소수가 된다.)
저자들의 벤치마크 프로그램에서 사용되는 데이터 접근 크기 분포는 다음과 같다. double-word 데이터 타입은 double-precision floating point를 표현하는 데 사용된다. (컴퓨터가 64비트의 주소를 사용. 32비트 주소를 사용하는 컴퓨터라면 word가 대부분을 차지할 것)
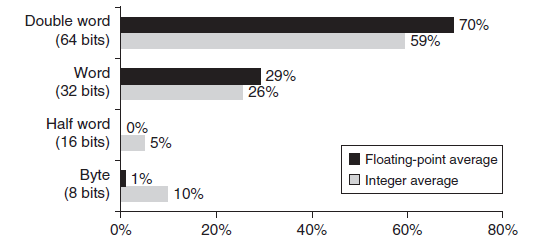
어떤 아키텍처에서는 바이트나 반워드 단위로 레지스터의 오브젝트에 접근하지만, 매우 드물게 일어난다. VAX의 경우 레지스터 접근의 12%이하로 발생하며 전체 피연산자 접근의 6% 정도를 차지한다.



