
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- pipelined
- nonblocking cache
- cache optimization
- pipelined cache
- cache coherence miss
- moesi
- Cache
- pipline hazards
- transactional memory
- store conditional
- Subquery
- structural hazard
- cache coherence
- branch prediction
- atomic exchange
- directory based coherence protocol
- sequential consistency
- speculative execution
- dependence
- multibanekd cache
- load linked
- register renaming
- relational model
- way prediction
- mesi
- 관계형 모델
- theta join
- dynamic scheduling
- ISA
- sql
- Today
- Total
공대생의 공부흔적
[컴퓨터구조#16] GPU (2) - 구조, G80, Memory Coalescing, Volta 본문
참고: Computer Architecture: A Quantitative Approach (5th edition) - 4.4.
지난 글에 이어, GPU 구조에 대해 더 살펴보고 최근의 GPU 아키텍처는 어떤지 더 알아보자.
목차
- GPU 아키텍처
- G80
- Memory Coalescing
- NVIDIA Volta
1. GPU 아키텍처
CUDA 쓰레드 블록
스레드 블록은 GPU의 위계적 구조 조직에 대한 abstraction이다. 한 블록 내 모든 스레드는 같은 커널 프로그램을 실행하며(SPMD), 프로그래머는 블록을 선언할 수 있다. 블록 크기는 1~512개의 concurrent 스레드로 이루어지며, 블록 모양은 1차원에서 3차원까지 가능하다. 스레드는 블록 내에서 스레드 id를 가지게 되고, 스레드 프로그램은 작업을 선택하고 공유 데이터 주소를 정하는 데 이 스레드 id를 사용한다.
같은 블록 내 스레드들은 작업을 수행하는 동안 데이터를 공유(GPU의 per-block shared memory(SW-managed cache): 하나의 스레드 block은 하나의 SM에서 돌아간다는 것을 상기해 보자. 즉 이 공유 메모리는 SM당 하나씩 존재하는 scratchpad memory이다.)하고, 동기화된다.
반면 서로 다른 블록의 스레드들은 이런 식으로 협력하는 것이 불가능하다. 각 블록은 다른 블록과 상관 없이 어떤 순서로든 실행될 수 있다. 아래 그림을 살펴보자. 하드웨어는 스레드 블록을 언제든 어떤 프로세서에든 할당할 수 있다. 각 블록은 실제 GPU 내 사용 가능한 SM에 따라 어떤 방식으로든 실행될 수 있다. 예를 들어 (왼쪽) 2개의 parallel processor가 사용 가능하다면 동시에 2개의 블록씩, (오른쪽) 4개의 parallel processor가 가능하다면 동시에 4개씩 실행시킬 수 있는 것이다.
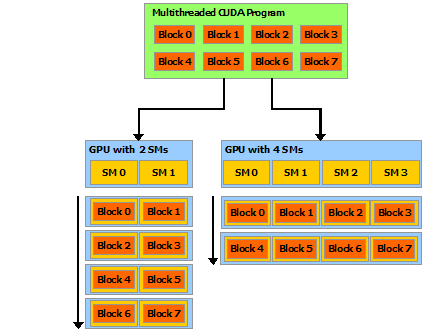
각 Streaming Multiprocessor(SM)는 8개의 Streaming Processor(SP), 그리고 2개의 Super Function Units(SFU)로 구성된다. L1 캐시와 명령어 fetch/dispatch의 프론트엔드 로직은 SM 내 모든 SP, SFU에서 공유되어 계산 밀도를 높일 수 있다(vector-like architecture). 또한, L1 캐시와 shared memory는 실제로는 합쳐져 64~128KB의 스토리지 용량을 차지한다. 명령어 idspatch의 경우 한 warp, 즉 32개의 스레드가 모두 동일한 명령어를 수행하게 된다.
2. G80
G80 GPU의 아키텍처 예시를 통해 GPU 동작에 대해서 조금 더 자세히 알아보자.
스레드 블록 실행
스레드들은 블록 단위로 SM에 할당되고, 각 SM에는 최대 8개의 블록이 들어갈 수 있다. G80의 SM은 최대 768개의 스레드를 가질 수 있다. 블록이 3개라면 블록당 256개의 스레드가, 블록이 6개라면 블록당 128개의 스레드가 들어가게 된다. 이 768이란 숫자는 최대치일 뿐이며, 컴파일 시 각 스레드가 사용하는 레지스터 양이 많다는 것을 알게 된다면 스레드 개수는 이보다 줄어들 수 있다. SM은 스레드와 블록 id 정보를 저장하며, 스레드 실행을 관리하고 스케줄링하여 각 스레드들이 concurrently 돌아갈 수 있도록 한다.
스레드 스케줄링
스레드 블록은 여러 개의 warp로 구성되어 있으며, 실행도 warp 단위로 진행된다. 즉 warp는 SM의 스케줄링 단위이다. G80의 경우 8개의 실행 unit이 존재하며, 하나의 warp를 실행하는 데 32 thread / 8 unit = 4 cycle이 소요된다. SM 내에서 한 warp 연산이 끝나면 실행할 다음 warp를 골라 실행하게 된다.
만약 SM에 3개의 블록이 할당되어 있고 각 블록이 256개의 스레드를 가진다면, 이 SM에는 몇 개의 warp가 존재하는 것일까? 각 블록은 256/32=8개의 warp로 구성되고, 이 블록이 3개 존재하므로 8*3=24, 총 24개의 warp가 이 SM에 존재하는 것이다.
Warp 스케줄링
SM 하드웨어는 warp 스케줄링 시 오버헤드가 없다. (zero-overhead: GPU에 모든 context 정보를 저장하고 있기 때문이다.) 다음 명령어의 피연산자가 모두 레지스터에 있어 ready인 warp들은 실행 자격이 있는 것으로 판단되고, 이러한 eligible warp들은 prioritized 스케줄링 정책에 따라 실행 대상으로 선택된다. 선택된 warp 내 모든 스레드들은 동일한 명령어를 처리한다.
또한, 앞서 보았듯, G80에서 동일한 명령어를 모든 스레드에 dispatch하는 데에는 4 clock cycle이 필요하다.
스케줄링 과정은 다음과 같다.
- 한 사이클에 하나의 warp instruction을 fetch한다. (from L1 I$, into any instruction buffer slot)
- 한 사이클에 하나의 ready-to-go warp를 발행한다. (from any warp instruction buffer slot)
- hazard 예방을 위해 피연산자 scoreboarding을 사용한다.
- → dependency tracking을 위한 것으로, Instruction Buffer 안에 있는 모든 명령어의 모든 레지스터 피연산자는 socreboarded된다. scoreboarding을 통해서 메모리/프로세서 파이프라인을 decouple한다. 즉, scoreboarding이 issue를 막기 전까지 모든 스레드는 계속해서 issue될 수 있다. 이는 메모리/프로세서 연산이 다른 메모리/프로세서 연산을 기다리며 실행될 수 있도록 허용한다.
- RR/warp age에 기반하여 선택한다.
프로그래밍 전략
global memory는 디바이스 메모리(DRAM)에 저장되어 있다. 이는 shared memory보다 훨씬 느리다. 따라서, 디바이스에서 연산을 수행하는 좋은 방법 중 하나는 데이터를 tile로 나누어 빠른 shared memory의 장점을 사용하는 것이다.
- 데이터를 shared memory에 들어갈 수 있도록 여러 subset으로 나눈다.
- 각 데이터 subset을 한 스레드 블록에서 처리할 수 있도록 한다:
- 여러 스레드를 사용하여 memory-level parallelism을 통해 global memory에서 shared memory로 해당 subset을 로드
- shared memory에서 해당 subset에 대한 연산 수행. 각 스레드는 다른 data element를 효율적으로 multi-pass할 수 있음
- 결과를 shared memory에서 global memory로 복사.
이 방법은 data fetch:computation 비율을 기존 1:1에서 1:m으로 개선시킬 수 있다. 1:1이라는 것은 낮은 computational intensity를 가져 메모리 대역폭이 커널의 실행시간을 결정하는 memory bound인 상황을 뜻한다. 1:m은 높은 arithmetic intensity를 가져 compute bound인 상황을 의미한다.
또한, 이 방법이 항상 적용 가능한 것은 아니다. 예를 들어, GEMM의 경우 행렬 차원에 따라 O(N^2), O(N^3)의 높은 data intensity를 가지기 때문에 이러한 프로그래밍 전략이 beneficial하지만, locality와 데이터 재사용이 없는 행렬-벡터 곱 같은 경우에는 이 전략을 통한 이득을 볼 수 없다(적용하더라도 계속 memory bound이다).
G80의 경우, 지난 글에서 살펴보았던 GEMM 예시에서 모든 스레드는 인풋 행렬 요소에 대해 global memory에 접근한다. FLOPS당 4B/s의 메모리 대역폭을 가진다. 최대 FLOP rating을 달성하기 위해서는(=to fully utilize GPU computational unit) 약 1.4TB/s의 대역폭이 필요하다. 실제 메모리 대역폭은 이보다 낮으며 메모리 대역폭에 의해 성능이 결정된다. (memory bound). 즉, 최대 FLOP rating 달성을 위해 global 메모리 접근을 최소화할 필요가 있다. 이에 대한 방법이 지난 글 마지막 부분에서 이야기했든 shared memory를 통해 tile을 활용하는 방법이다.
Tiled algorithms
각 element를 shared memory로 로드해 커널이 local version을 사용할 수 있도록 만드는 것이다. 각 스레드는 Ad와 Bd의 subset에 접근하게 되고, output Cd의 경우 한 스레드가 tile의 각 element를 맡아서 계산한다.
CPU vs. GPU에서의 tiling 차이
- CPU: L1,L2$를 tile data storage로 사용한다. L1,L2$는 하드웨어에 의해 컨트롤되어 소프트웨어가 직접 캐시 내 데이터를 통제하는 것이 불가능하다. (indirectly control)
- GPU: tile data를 저장하는 shared memory는 SW-programmable하므로, 소프트웨어가 메모리 내 데이터를 직접 통제할 수 있다. 또한, shared memory를 채우기 위해 스레드 블록 내 스레드들이 데이터를 가져오기 위해 협력한다. 즉 스레드들은 global data에서 다같이 데이터를 가져오고, 한번 가져온 이후에는 shared memory 내 자기 부분을 읽고 partial sum을 계산하는 것이다.
즉, tile algorithm을 적용하기 전에는 A의 한 element가 global memory에서 A.width번 읽어와져야 했다면, 적용한 후에는 A.width/TILE_WIDTH(=#tiles)만큼만 읽어와지면 된다. 즉 reduction factor는 tile width가 된다.

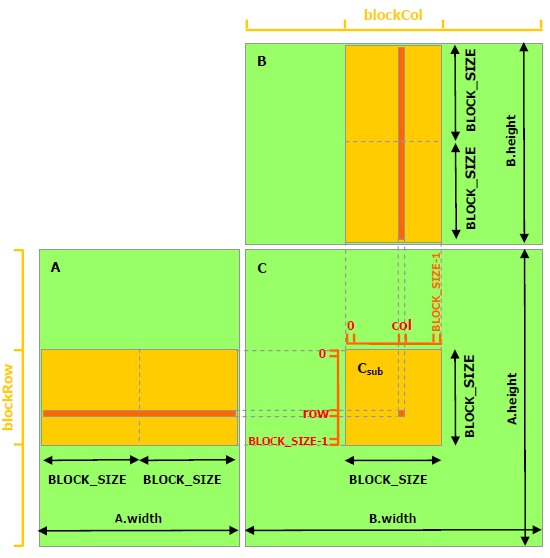
shared memory를 적용할 수 있도록 커널 함수를 수정해 보자. 이 코드에서는 편의상 A,B,C가 모두 Width*Width의 크기를 가진다고 가정했다.
__global__ void MatrixMulKernel(float* Ad, float* Bd, float* Cd, int Width)
{
__shared__float Ads[TILE_WIDTH][TILE_WIDTH];
__shared__float Bds[TILE_WIDTH][TILE_WIDTH];
// Calculate the row index of the Cd element and A/B
int Row = blockIdx.y*TILE_WIDTH + threadIdx.y;
int Col = blockIdx.x*TILE_WIDTH + threadIdx.x;
// Cvalue: store the element of the matrix & computed by the thread
float Cvalue = 0;
// Loop over Ad, Bd tiles required to compute the Cd element
for (int m=0; m<Width/TILE_WIDTH; ++m){
// Collaborative loading of Ad, Bd tiles into shared memory
Ads[threadIdx.y][threadIdx.x] = Ad[Row*Width+(m*TILE_WIDTH+threadIdx.x)];
Bds[threadIDx.y][threadIdx.x] = Bd[(m*TILE_WIDTH+threadIdx.y)*Width+Col];
__synchthreads();
// partial Matmul
for (int k=0; k<TILE_WIDTH; ++k)
Cvalue += Ads[threadIdx.y][k]*Bds[k][threadIdx.x];
__synchthreads();
}
Cd[Row*width_C+Col] = Cvalue;
}이때 __synchthreads() 함수에 주목하자. 모든 스레드가 __synchthreads()가 있는 코드에서 다 완료되는 것이 보장된다. 첫 번째 synch에서는 global memory에서 shared memory로 데이터를 복사해오기 때문에 synch가 필요하다. 두 번째 synch는 만약 이 synch가 없는 경우 다음 for loop로 넘어가서 Ads, Bds를 load해오는 스레드가 생길 수 있기 때문에(Ads, Bds overwrite) 모든 partial sum이 끝나길 기다렸다가 확실하게 다음 타일로 넘어가도록 해야 한다.
tile algorithm을 적용한 뒤 G80 성능을 다시 살펴보자. TILE_WIDTH=16이라 한다면 각 스레드 블록은 16*16=256개의 스레드를 가지게 된다. Cd의 width를 1024라 한다면 총 (1024/16)*(1024/16)=64*64=4096개의 스레드 블록을 갖게 된다. 각 스레드 블록은 global memory에서 2*256=512번의 float load를 수행하고 이는 256*(2*16)=8192개의 곱셈,덧셈 연산을 포함한다. 이 경우 메모리 대역폭이 더이상 limiting factor가 되지 않는다.
*얼마나 많은 스레드가 사용될 수 있는지에 대한 limiting factor는 hard limitation(하드웨어에 의해 총 몇 개의 스레드가 사용 가능한지), soft limitation(소프트웨어에 의해 결정되는 부분 - 스레드 내 얼마나 많은 레지스터가 사용되는지 등), shared memory limitation(공유 메모리에 할당되는 크기) 등이 있다.
3. Memory Coalescing
메모리 코얼레싱이란 GPU의 스레드가 메모리에 접근할 때 연속된 메모리 주소 접근을 통해 성능을 개선하는 것을 말한다.
행렬곱 커널 함수를 다시 살펴보자. 각 스레드는 행렬A는 row-wise로(행 접근), B는 column-wise로(열 접근) 접근한다.
__global__ void MatrixMulKernel(float* A, float* B, float* C, int Width)
{
// Calculate the row index of the C element and A
int Row = blockIdx.y * blockDim.y + threadIdx.y;
// Calculate the column index of C and B
int Col = blockIdx.x * blockDim.x + threadIdx.x;
if ((Row < Width) && (Col < Width)) {
float Cvalue = 0;
// each thread computes one element of the block sub-matrix
for (int k = 0; k < Width; ++k)
Cvalue += A[Row*Width+k] * B[k*Width+Col];
C[Row*Width+Col] = Cvalue;
}
}그렇다면 row-wise와 column-wise 중 어떤 접근 패턴이 더 적절할까?
CPU에서는 row-wise가 더 적절하다.
하지만 GPU에서는 (우리의 직관과는 다르게) column-wise가 더 적절하다. GPU에서는 warp 단위로 명령이 실행되므로, column-wise로 접근 시 여러 스레드가 각각 연속된 메모리에 접근할 수 있다. 그림으로 표현하면 다음과 같다. (한 warp에 4개의 스레드가 있다고 간단하게 생각해 보자.)
| B | T0 | T1 | T2 | T3 |
| ↓ | 0,0 | 0,1 | 0,2 | 0,3 |
| 1,0 | 1,1 | 1,2 | 1,3 | |
| 2,0 | 2,1 | 2,2 | 2,3 | |
| 3,0 | 3,1 | 3,2 | 3,3 |
각 load iteration마다 T0~T3 4개의 스레드가 실행된다. 즉 각 스레드가 다음과 같이 메모리 상에서 연속된 주소에 접근할 수 있는 것이다. -> B 접근은 coalesced된다.
| load iter 0 | load iter 1 | ... | |||||||
| T0 | T1 | T2 | T3 | T0 | T1 | T2 | T3 | T0 | |
| 0,0 | 0,1 | 0,2 | 0,3 | 1,0 | 1,1 | 1,2 | 1,3 | 2,0 | ... |
반면 row-wise 접근인 A를 생각해보자.
| A | → | |||
| T0 | 0,0 | 0,1 | 0,2 | 0,3 |
| T1 | 1,0 | 1,1 | 1,2 | 1,3 |
| T2 | 2,0 | 2,1 | 2,2 | 2,3 |
| T3 | 3,0 | 3,1 | 3,2 | 3,3 |
이번에는 각 iteration마다 T0~T3 스레드가 서로 떨어져 있는 메모리에 접근해야 한다. A 접근은 coalesced되지 않는다.
| T0(iter0) | T0(iter 1) | T2(iter 2) | T3(iter 3) | T1(iter 0) | T1(iter 1) | T1(iter 2) | T1(iter 3) | T2(iter 0) | |
| 0,0 | 0,1 | 0,2 | 0,3 | 1,0 | 1,1 | 1,2 | 1,3 | 2,0 | ... |
parallel reduction
트리 형식으로 여러 element의 합을 동시에 병렬적으로 계산하는 방식이다.
__global__ void plus_reduce(int *input, unsigned int N, int* total) {
unsigned int tid = threadIdx.x;
unsigned int i = blockIdx.x*blockDim.x+threadIdx.x;
// Each block loads its elements into memory,
// padding with 0 if N is not a multiple of blocksize
__shared__ int x[blocksize];
x[tid] = (i<N) ? input[i] : 0;
__synchthreads();
// Every thread now holds 1 input value in x[]
// Build summation tree over elements.
for (int s=blockDim.x/2; s>0; s=s/2) {
if (tid<s) x[tid] += x[tid+s];
__synchthreads();
}
// Thread 0 now holds the sum of all input values to this block.
// Have it add that sum to the running total
if (tid==0) atomicAdd(total, x[tid]);
}* 조건으로 (tid%2... 등등 보다) tid<s를 사용하는 이유: warp 내 스레드들의 control divergence를 피해 task가 더 빨리 완료되도록 만들게 하기 위함
**GPU에서도 다음과 같은 atomic operation을 적용할 수 있다. 즉 read-modify-write의 과정이 원자적으로 발생한다. 하지만 이러한 연산들은 GPU에서는 높은 cost를 가지므로 자주 쓰면 안 되고 조심스럽게 사용해야 한다.
- signed/unsigend int에 대한 associative 연산, add/sub/min/max.., and/ox/xor, in/decrement, exchange, compared and swap
4. NVIDIA Volta
최근 GPU 아키텍처들의 기본이 되는 NVIDIA Volta 아키텍처에 대해 알아보자.
Volta는 다음과 같은 요소들로 구성되어 있다.
- 딥러닝에 최적화된 새로운 SM
- NVLink: 여러 GPU간의 지정된 네트워크
- HBM2 메모리: 더 빠르고 효율적
- Volta Multi-Process Service (MPS): GPU를 공간적으로 나누어서 서로 다른 응용을 동시에 돌림
- Unified memory 및 주소 변환 개선
G80과 비교 시 더 많은 SM이 들어가 있다. PE가 많을수록 (응용이 아키텍처와 잘 맞는 병렬성을 가지는 한) 성능이 더 좋아진다.
SM은 shared frontend (instruction$, warp scheduler ,dispatch unit)을 가지며, 여러 개의 연산 유닛과 tensor core를 가진다. tensor core는 4*4 행렬계산에 최적화된 가속기이다. SM당 8개의 tensor core가 존재한다. 인풋으로는 fp16을 받고, 아웃풋으로는 fp32를 계산한다.
L1 데이터 캐시와 shared memory는 합쳐서 SM당 128KB를 차지하며, 이 용량 내에서 얼만큼을 L1 데이터 캐시에 할당하고 얼만큼을 shared memory에 할당할지는 프로그래머가 정할 수 있다.
또한, GPU의 memory만 사용하는 것이 아니라 CPU메모리에도 접근할 수 있다. locality가 있는 경우 CPU 페이지를 GPU 메모리에 복사하여 사용하고, 그렇지 않은 경우 GPU에서 직접 CPU 메모리에 접근한다. 이러한 unified memory 접근은 CPU 메모리와 GPU 메모리 간의 추상화된 메모리를 제공한다.
'Computer Architecture' 카테고리의 다른 글
| [컴퓨터구조#17] Domain Specific Architecture - TPU (0) | 2024.06.10 |
|---|---|
| [컴퓨터구조#15] GPU (1) - 기초, CUDA, GEMM example (2) | 2024.06.09 |
| [컴퓨터구조#14] SIMD (1) | 2024.06.08 |
| [컴퓨터구조#13] 가상 메모리 (Virtual Memory) (1) | 2024.06.08 |
| [컴퓨터구조#12-2] 일관성 (Consistency) - Memory Consistency, Sequential Consistency, Relaxing SC (1) | 2024.06.08 |


